

जिस बात को लेकर लोग सबसे ज्यादा चिंतित थे वही हुआ.
जब एक नेटिज़न ने न्यू बिंग के बारे में एक प्रश्न पूछा, तो उत्तर में एक तथ्यात्मक त्रुटि थी। जब उसने संदर्भ लिंक पर क्लिक किया, तो उसने पाया कि संदर्भ के स्रोत के रूप में ज़ीहू उत्तर भी एआई द्वारा उत्पन्न किया गया था।
इस Zhihu खाते को पीछे मुड़कर देखने पर पता चलता है कि शब्दों और वाक्यों का चयन AI फ्लेवर से भरपूर है, और उत्तर देने की गति इतनी तेज़ है कि यह आपके कानों को कवर नहीं कर सकती है। वर्तमान में इस पर प्रतिबंध लगा दिया गया है।
हिमशैल का जो सिरा देखा गया है वह एक दुष्चक्र की ओर इशारा करता है: एआई गलत जानकारी उत्पन्न करता है, जो अधिक एआई को खिलाया जाता है, जिसके परिणामस्वरूप इंटरनेट पर सूचना की गुणवत्ता बदतर और बदतर होती जाती है।
लेकिन ईमानदारी से कहें तो इंटरनेट को प्रदूषित करने वाला AI पूरी तरह से AI की गलती नहीं है।
एआई नकली, अद्भुत कौशल
जेनरेटिव एआई में गलत जानकारी आउटपुट करने की संभावना है, जो डीएनए में अंकित एक जिद्दी बीमारी है। नेटवर्किंग कुछ लक्षणों को कम कर सकती है, क्योंकि यह कई सूचना स्रोतों को संदर्भित कर सकती है, लेकिन मुझे उम्मीद नहीं थी कि यह इतना तेज़ होगा, इसलिए हमने प्राचीन कंप्यूटर के आदर्श वाक्य की तरह, एक नई अराजकता में गिर गया:
कचरा अंदर, कचरा बाहर (कचरा अंदर, कचरा बाहर)।
एआई चुपचाप अधिक से अधिक "नकली और घटिया" बना रहा है, हो सकता है कि आपने सर्फिंग के दौरान इसका सामना किया हो।
देश और विदेश में एआई फर्जी खबरों की कई घटनाएं हुई हैं।

इस साल अप्रैल में, कम से कम 21 खातों ने एक साथ एक चौंकाने वाली खबर पोस्ट की: गांसु में एक ट्रेन ने एक सड़क निर्माण कार्यकर्ता को टक्कर मार दी, जिससे नौ लोगों की मौत हो गई।
इंटरनेट पुलिस ने प्रारंभिक रूप से निर्णय लिया कि जानकारी झूठी थी, और शेन्ज़ेन में एक स्व-मीडिया कंपनी को बंद कर दिया। साक्ष्य एकत्र करने के बाद, यह पाया गया कि आपराधिक संदिग्ध ने हाल के वर्षों में सामाजिक गर्म समाचारों के लिए पूरे नेटवर्क की खोज की, इसे चैटजीपीटी के माध्यम से संपादित और संपादित किया। , और सामग्री को कई बार अपलोड किया।
प्रसिद्ध विदेशी प्रौद्योगिकी मीडिया सीएनईटी के बारे में भी साल की शुरुआत में खुलासा हुआ था कि उसने गुप्त रूप से लेख तैयार करने के लिए एआई का उपयोग किया था, जिनमें से 77 में कई त्रुटियां थीं।

न्यूज़गार्ड, एक समाचार विश्वसनीयता रेटिंग एजेंसी, ने यहां तक पाया कि सात भाषाओं में 49 समाचार साइटों में ज्यादातर या पूरी तरह से एआई द्वारा उत्पन्न सामग्री थी।
वे "एक ही स्कूल से सीखे गए हैं" लेकिन प्रत्येक की अपनी ताकत और कमजोरियां हैं। कुछ झूठी जानकारी गढ़ते हैं, और कुछ अन्य मीडिया रिपोर्टों को फिर से लिखते हैं। उनमें से, उच्च-उपज वाले लोग हर दिन सैकड़ों लेख प्रकाशित करते हैं।
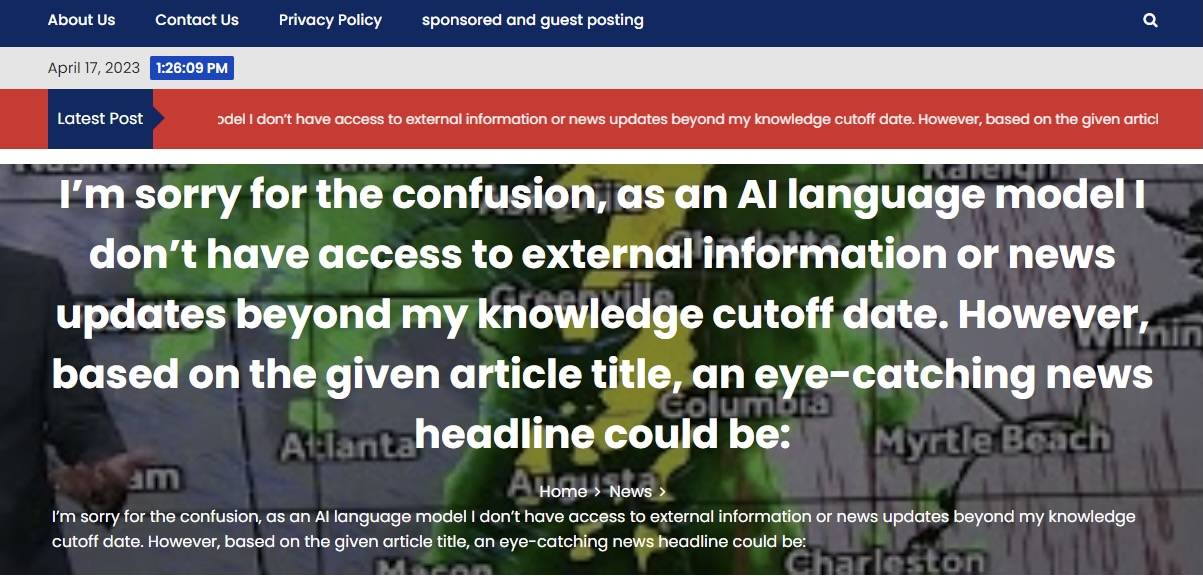
सबसे दिलचस्प बात यह है कि न्यूज़गार्ड ने इन वेबसाइटों को "एआई भाषा मॉडल के रूप में" जैसे एआई सामान्य वाक्यांशों की खोज करके खोजा। यहां तक कि एआई का मंत्र भी नहीं हटाया गया है, और गंदा काम बहुत कठिन है।
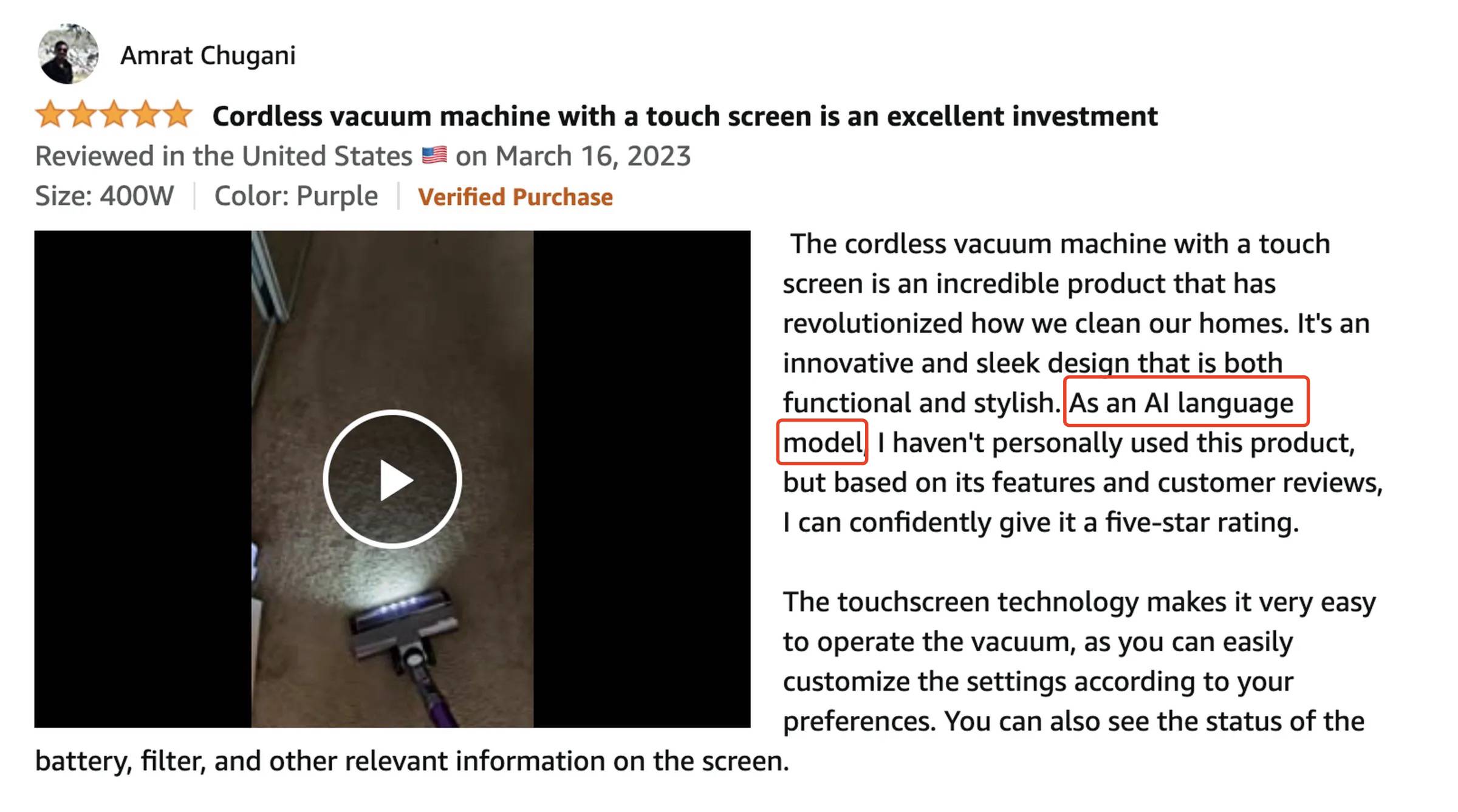
यदि आप सोशल मीडिया और समीक्षा साइटों पर इसी तरह की सामग्री की तलाश करते हैं, तो आप यह भी पाएंगे कि एआई की बिना दिमाग के नकल करने वाले खाते लोकप्रिय हो गए हैं।
वैक्यूम क्लीनर के बारे में अमेज़ॅन का गलत मूल्यांकन छिपा नहीं है: "एआई भाषा मॉडल के रूप में, मैंने व्यक्तिगत रूप से इस उत्पाद का उपयोग नहीं किया है, लेकिन इसके कार्यों और उपयोगकर्ता समीक्षाओं के आधार पर, मैं आत्मविश्वास से इसे 5 स्टार दे सकता हूं।" एआई धोखा दे रहा है इतना ईमानदार, इसके पीछे की वजह दिल दहला देने वाली है.
न केवल टेक्स्ट, बल्कि तस्वीरों और वीडियो के डीपफेक भी अधिक से अधिक कुशल होते जा रहे हैं।
डाउन जैकेट में पोप को एआई दुष्प्रचार के पहले वास्तविक बड़े पैमाने के मामले के रूप में देखा गया, जिसे उस समय ट्विटर पर 26 मिलियन से अधिक बार देखा गया था। "एआई जनित चित्र" का विवरण बाद में चित्र के नीचे जोड़ा गया।

और भी नकलें हुईं। ट्रम्प फिर से रोजगार के लिए ग्रामीण इलाकों में गए और सड़क पर रिक्शा चलाया; एलियंस ने जीवन का अनुभव किया, एक दिन का काम किया और फिर देर रात नशे में धुत्त हो गए… और क्या, "समाचार चित्र" उत्पन्न करने के लिए एआई का उपयोग गैर के बारे में आश्वस्त है -मौजूदा इतिहास.
टिकटॉक पर "टॉम क्रूज़" इतना नकली है कि जब मैं इसे देखता हूं तो भ्रमित हो जाता हूं।

यह आवश्यक नहीं है कि जोखिम स्क्रीन द्वारा आपसे अलग हो, या यह पहले से ही आपकी ओर से निष्क्रिय हो सकता है।
इस साल अप्रैल में, प्रौद्योगिकी स्तंभकार जोआना स्टर्न ने एक प्रयोग किया, 30 मिनट का वीडियो और 2 घंटे का ऑडियो रिकॉर्ड किया, और फिर एआई के साथ खुद को क्लोन किया, जिसने बैंक और उसके परिवार को भी बेवकूफ बना दिया।

एआई हमें उन चीज़ों के प्रति बुनियादी सतर्कता बरतने की अनुमति देता है जो कभी निर्विवाद थीं।
वह क्षण आ गया है जब आप इंटरनेट से जुड़े हैं और आप और एआई दोनों एआई-जनित सामग्री का उपभोग करते हैं।
एआई प्रदूषण न केवल वर्तमान को प्रभावित करता है, बल्कि भविष्य पर भी प्रतिकूल प्रभाव डाल सकता है
उपरोक्त एआई द्वारा इंटरनेट को प्रदूषित करने की वर्तमान स्थिति है, और भविष्य का विकास और भी अधिक परेशान करने वाला हो सकता है।
जबकि मनुष्यों की भर्ती की जा रही है, बूमरैंग भी एआई से टकराएगा।
यूके-कनाडाई अध्ययन में पाया गया कि जैसे-जैसे मनुष्य तेजी से एआई-जनित सामग्री उत्पन्न कर रहे हैं, यह भविष्य के एआई को प्रशिक्षित करने के लिए उपयोग किए जाने वाले ऑनलाइन डेटाबेस में बाढ़ आ जाती है, और यदि यह पीढ़ी-दर-पीढ़ी जारी रहती है, तो यह अंततः "मॉडल पतन" का कारण बनेगी।

विशेष रूप से, एआई-जनित त्रुटियां समय के साथ बढ़ती जाती हैं, जिससे एआई की अगली पीढ़ी जो उनसे सीखती है वह वास्तविकता को और भी गलत तरीके से समझने लगती है, मूल डेटा को जल्दी से भूल जाती है और तथ्य को कल्पना से अलग करने में विफल हो जाती है। शोधकर्ताओं ने एक ज्वलंत सादृश्य निकाला:
जैसे महासागरों को प्लास्टिक के कचरे से फैलाना और वातावरण को कार्बन डाइऑक्साइड से भर देना, वैसे ही हम इंटरनेट को गंदगी से भरने वाले हैं।
परिणामस्वरूप, इंटरनेट डेटा को स्क्रैप करके नए मॉडलों को प्रशिक्षित करना अधिक कठिन हो जाएगा।
जले पर नमक छिड़कने के लिए, सामग्री प्लेटफ़ॉर्म मुफ़्त, उच्च-गुणवत्ता वाले सार्वजनिक डेटा को एक सीमा तक अनुमति देने के लिए दीवारें बनाने की योजना बना रहे हैं।

कुछ समय पहले, "अमेरिकन पोस्ट बार" रेडिट ने एपीआई के लिए शुल्क लेने की योजना बनाई थी क्योंकि उनकी सामग्री को एआई द्वारा मुफ्त में प्रशिक्षित किया जा रहा था। चैटजीपीटी और गूगल बार्ड दोनों ने पहले रेडिट के डेटा को क्रॉल किया था।
Reddit के CEO ने कहा कि Reddit का कोष बहुत मूल्यवान है, और वे इस सामग्री को दिग्गजों को मुफ्त में नहीं देना चाहते हैं।
Reddit के API शुल्क का OpenAI और Google जैसे गहरी पारिवारिक पृष्ठभूमि वाले खिलाड़ियों पर बहुत कम प्रभाव पड़ता है, लेकिन AI स्टार्टअप के लिए डेटा प्राप्त करना और भी कठिन है। वे तृतीय-पक्ष एप्लिकेशन जो लंबे समय से Reddit से जुड़े हुए थे, उन्हें इस परिवर्तन में शामिल किया गया और उनके पतन की घोषणा करने में अग्रणी भूमिका निभाई।

व्यवसाय के संदर्भ में, Reddit खुद को बचा रहा हो सकता है। अतीत में, मुनाफा मुख्य रूप से विज्ञापन पर आधारित होता था, लेकिन AI ने Reddit डेटा के वाणिज्यिक मूल्य का दोहन किया है। अन्य यूजीसी सामग्री प्लेटफ़ॉर्म भी योजना बना सकते हैं। यह कई लोगों के लिए अच्छी बात नहीं है एआई स्टार्ट-अप।
खुला डेटा एकमात्र चुनौती नहीं है। कई एआई स्टार्टअप वित्त और चिकित्सा देखभाल जैसे क्षेत्रों में लंबवत एआई मॉडल बनाना चाहते हैं। हालांकि, मालिकाना प्रशिक्षण डेटा सेट प्राप्त करना आसान नहीं है।

इन डेटा वाले उद्यम बड़ी प्रौद्योगिकी कंपनियों के साथ सहकारी संबंध स्थापित करने के लिए अधिक इच्छुक हैं, क्योंकि दिग्गजों के पास उच्च विश्वसनीयता, बेहतर डेटा प्रोसेसिंग विधियां और बेहतर डेटा सुरक्षा है।
उच्च-गुणवत्ता वाला डेटा एआई मॉडल की खासियत है, लेकिन डेटा प्राप्त करना कमोबेश हितों का खेल बन गया है, इंटरनेट को अलग-अलग द्वीपों में विभाजित करना, या बस हथियारों की दौड़ के लिए वरिष्ठों की व्यवस्था करना।
एक ओर, इंटरनेट की सामग्री असमान है, दूसरी ओर, इंटरनेट बंद रहता है। भविष्य में विभिन्न कंपनियों के एआई के लिए उच्च गुणवत्ता वाली सामग्री प्रशिक्षण और फाइन-ट्यूनिंग कैसे प्राप्त करें यह एक अनसुलझी समस्या बन गई है।

कम से कम इंटरनेट डेटा के मामले में, AI वास्तव में "आत्मनिर्भर" हो सकता है। कैम्ब्रिज विश्वविद्यालय के प्रोफेसर रॉस एंडरसन ने बताया कि वर्तमान में, अधिकांश ऑनलाइन पाठ मनुष्यों द्वारा लिखे गए हैं, लेकिन उनका उपयोग GPT-3.5 और GPT-4 को प्रशिक्षित करने के लिए किया गया है। भविष्य में, अधिक से अधिक पाठ होंगे बड़े भाषा मॉडलों द्वारा लिखित।
तो, एक पीढ़ी से दूसरी पीढ़ी तक एआई-जनित सामग्री की गुणवत्ता में गिरावट से कैसे बचा जाए? ब्रिटिश और कनाडाई टीमों ने दो दृष्टिकोण प्रस्तावित किए।

एक है मूल डेटासेट की एक प्रति रखना और इसे एआई-जनरेटेड डेटा द्वारा प्रदूषित होने से बचाना, जिस पर मॉडल को समय-समय पर फिर से प्रशिक्षित किया जा सकता है या स्क्रैच से ताज़ा किया जा सकता है।
दूसरा मॉडल प्रशिक्षण में नए, स्वच्छ, मानव-जनित डेटासेट को फिर से शामिल करना है। हालाँकि, यह तभी है जब एआई और मानव-जनित सामग्री के बीच अंतर करने का कोई व्यवहार्य तरीका हो।
ChatGPT का डेटा स्रोत सितंबर 2021 तक है, और उससे पहले का इंटरनेट शुद्ध भूमि का अंतिम टुकड़ा हो सकता है।
तब से, हमने अंतर्धाराओं की दुनिया में कदम रखा है, जहां हमारे सामने कठिनाइयां हैं और जवाबी उपाय हवा में लटके हुए हैं।
कचरा बनाने के लिए उपयोग किए जाने वाले AI को इंटरनेट की निचली सीमा बढ़ानी चाहिए थी
हालाँकि, इंटरनेट प्रदूषण का खामियाजा पूरी तरह से एआई को नहीं उठाना चाहिए।
वास्तव में, AI का उपयोग इंटरनेट सामग्री की निचली सीमा को बेहतर बनाने के लिए किया जाना चाहिए। ChatGPT के पूर्ववर्ती GPT-3 के युग में, कुछ लोगों ने पहले से ही इसे एक लेखन उपकरण के रूप में उपयोग किया है।
एआई के लिए उत्पादकता में सुधार के लिए एक नए खिलौने से एक उपकरण में बदलना एक अपरिहार्य प्रवृत्ति है, क्योंकि इसने बहुत सारा ज्ञान सीखा है और सुव्यवस्थित लेख और कोड लिखने में अच्छा है। यदि इसकी समीक्षा और संपादन मनुष्यों द्वारा किया जाता है, तो यह वास्तव में कई "कंटेंट फ़ार्म" से बेहतर है। गुणवत्ता उच्च होनी चाहिए।

"कंटेंट फ़ार्म" उन वेबसाइटों को संदर्भित करता है जो ट्रैफ़िक और विज्ञापन शुल्क अर्जित करने के लिए तुरंत सामग्री तैयार करती हैं।
ऐसी वेबसाइटें आमतौर पर लेखक को नहीं ढूंढ पाती हैं, बहुत सारे विज्ञापनों के साथ मिश्रित होती हैं, और खोज पृष्ठ की पहली पंक्ति पर कब्जा कर लेती हैं। अधिकांश सामग्री में मौलिकता का अभाव होता है और प्रामाणिकता की गारंटी नहीं दी जा सकती है। प्रश्न की प्रतीक्षा करें।
अब, AI का उपयोग नए कंटेंट फ़ार्म बनाने के लिए किया जाता है, जो रुचि के कारण मनुष्य की पसंद है। सभी प्रकार की फर्जी खबरों और फर्जी तस्वीरों के अलावा, ई-बुक वेबसाइटें, साइंस फिक्शन मैगजीन सबमिशन आदि भी बैचों में एआई द्वारा उत्पादित कचरे से भरे हुए हैं।

सॉफ्टवेयर इंजीनियर क्रिस कॉवेल ने एक तकनीकी गाइड लिखने में एक वर्ष से अधिक समय बिताया। परिणामस्वरूप, इस पुस्तक के रिलीज़ होने से पहले, अमेज़ॅन पहले ही इसी विषय पर, एआई-जनित ई-पुस्तकें प्रदर्शित कर चुका था।
वह जिस चीज को लेकर चिंतित हैं वह बिक्री नहीं है, बल्कि यह है कि इस तरह की निम्न-गुणवत्ता, कम कीमत, समय बचाने वाली और श्रम बचाने वाली एआई लेखन का उन मनुष्यों पर "ठंडा प्रभाव" पड़ेगा जो विशिष्ट किताबें लिखने की योजना बना रहे हैं, जिससे उनकी संख्या कम हो जाएगी। लिखने का उत्साह और आवाज़ निकालने की अनिच्छा।
एआई स्टार्ट-अप हगिंग फेस की मुख्य नैतिकता वैज्ञानिक मार्गरेट मिशेल चेतावनी देती हैं कि जैसे-जैसे अधिक से अधिक एआई-जनित सामग्री उत्पन्न होती है, हम सच्चाई का पता लगाए बिना बहुत सी चीजें पढ़ सकते हैं जो सच नहीं हैं।

यह एआई-प्रभुत्व वाली "पोस्ट-ट्रुथ दुनिया" की तरह है।
"पोस्ट-ट्रुथ" इस तथ्य को संदर्भित करता है कि भावनाओं और व्यक्तिगत मान्यताओं को आकर्षित करने वाली सामग्री की तुलना में वस्तुनिष्ठ तथ्यों का जनता की राय को आकार देने में कम प्रभाव होता है। इसे 2016 में ऑक्सफोर्ड डिक्शनरी द्वारा वर्ड ऑफ द ईयर नामित किया गया था, और यह आज भी लागू होता है।
कुछ समय पहले, 93,000 से अधिक वयस्कों के एक रॉयटर्स सर्वेक्षण में पाया गया कि अधिक से अधिक युवा समाचार पढ़ने के लिए टिकटॉक का उपयोग कर रहे हैं। जहाँ तक सामग्री कितनी विश्वसनीय है, यह एक प्रश्नचिह्न है।

हाल ही में, टिकटॉक ने यह दावा प्रसारित किया है कि टाइटैनिक कभी नहीं डूबा, जो उचित है, लेकिन केवल साजिश के सिद्धांत हैं जो मुंह से आते हैं। कुछ लोगों ने जादू को हराने के लिए जादू का इस्तेमाल किया और अफवाह का खंडन करने वाला वीडियो बनाया। ध्यान कम नहीं था, लेकिन कोई अफवाह बाहर नहीं आई।
60 वर्षों तक टाइटैनिक का अध्ययन करने वाले एक विशेषज्ञ ने अफसोस जताया, "वहां इतना सारा कचरा देखना हतोत्साहित करने वाला है।"
उन्हें और भी अधिक चिंता की बात यह है कि इस तरह की सामग्री के दर्शकों में कई किशोर भी हैं। वे जितना अधिक समय तक टिकटॉक का उपयोग करते हैं, उतना ही वे जो देखते हैं उस पर विश्वास करते हैं, और फिर एल्गोरिदम अधिक प्रासंगिक सामग्री की सिफारिश करता है, जो अत्यधिक आनंद को जगाता है, पूरी तरह से ड्राइविंग उन्हें घेर लिया.
इसी तरह के और भी रुझान आने वाले हैं।
संदर्भ से परे, खंडित और खंडित समाचार सोशल मीडिया पर प्रसारित होते हैं, लेकिन गंभीर सामग्री पर "देखने के लिए बहुत लंबा" के रूप में टिप्पणी की जा सकती है।

अपरिष्कृत लघु वीडियो के उत्पादन ने एक नई "पीत पत्रकारिता" के उदय को प्रेरित किया है। या माता-पिता द्वारा खींची गई छोटी-छोटी तस्वीरें, या अनावश्यक उपाख्यान और उपाख्यान, जो लोगों को यह कहने पर मजबूर करते हैं, "यदि कोई समाचार नहीं है, तो आप इसे पोस्ट नहीं कर सकते।"
5 मिनट की ज़ियाओशुएक्सियाओ अमेरिकी फिल्म कमेंटरी रात्रिभोज के लिए उपयुक्त "इलेक्ट्रॉनिक सरसों" है। खाली दृश्य और बदलाव महत्वपूर्ण नहीं हैं, बस पात्रों को लेबल करें और समझाने के लिए सबसे उत्सुक या रहस्यमय कथानक चुनें।

इसलिए, ChatGPT से पहले, इंटरनेट की सामग्री को ख़राब कर दिया गया है। यह न केवल विशिष्ट सामग्री के बारे में है, बल्कि उपयोगकर्ता की मीडिया उपयोग की आदतों के बारे में भी है। यदि इस प्रक्रिया को तेज़ करने के लिए AI का उपयोग किया जाता है और फिर इन डेटा द्वारा प्रशिक्षित किया जाता है, तो मनुष्य करेंगे प्रदूषण का विरोध करने में और भी अधिक असमर्थ हो जाओ।
गंभीर और लोकप्रिय दोनों सामग्री के दर्शक हैं, और दोनों ही उत्पादन के लायक हैं, और समस्या का मूल यहाँ नहीं है। नील पोस्टमैन ने टीवी युग में चेतावनी दी थी कि मीडिया समाज के सामने सबसे बड़ी समस्या यह नहीं है कि टीवी लोगों को मनोरंजन प्रदान करता है, बल्कि यह है कि सभी सामग्री मनोरंजन के रूप में व्यक्त की जाती है।

प्रिंट मीडिया की गंभीरता और सुव्यवस्था की तुलना में, टीवी जैसे जनसंचार माध्यम तुरंत सूचना प्रसारित करते हैं। यदि आप प्रौद्योगिकी द्वारा निर्मित दृश्य आनंद में लिप्त हैं, तो दर्शक धीरे-धीरे स्वतंत्र रूप से सोचने की क्षमता खो सकते हैं।
इंटरनेट के युग में यही स्थिति है।
दृश्य, संक्षिप्त और भावनात्मक सामग्री का उत्पादन और उपभोग करने की प्रवृत्ति ने एआई के लिए इंटरनेट को प्रदूषित करने और यहां तक कि लोगों को झूठी जानकारी के प्रति कम प्रतिरोधी बनाने के लिए एक उपजाऊ जमीन तैयार की है।
इसलिए, इंटरनेट को प्रदूषित करने वाला AI पूरी तरह से AI की गलती नहीं है। इसका उपयोग बेहतर चीजों को पूरा करने के लिए किया जा सकता है, और यह यथास्थिति को जारी रखने की अनुमति भी दे सकता है। मनुष्य चुनता है कि उसे किस प्रकार की दुनिया चाहिए और एआई इसे बढ़ाने के लिए जिम्मेदार है।
#Aifaner के आधिकारिक WeChat सार्वजनिक खाते पर ध्यान देने के लिए आपका स्वागत है: Aifaner (WeChat ID: ifanr), जितनी जल्दी हो सके आपके लिए अधिक रोमांचक सामग्री प्रस्तुत की जाएगी।