

एजीआई (कृत्रिम सामान्य बुद्धिमत्ता) संपूर्ण एआई उद्योग की पवित्र कब्र है।
पूर्व ओपनएआई मुख्य वैज्ञानिक इल्या सुत्सकेव ने पिछले साल एक विचार व्यक्त किया था: "जब तक हम अगले टोकन की अच्छी तरह से भविष्यवाणी कर सकते हैं, हम मनुष्यों को एजीआई हासिल करने में मदद कर सकते हैं।"
ट्यूरिंग पुरस्कार विजेता जेफ्री हिंटन, जिन्हें गहन शिक्षा के जनक के रूप में जाना जाता है, और ओपनएआई के सीईओ सैम ऑल्टमैन दोनों का मानना है कि एजीआई दस साल के भीतर या उससे भी पहले आ जाएगा।
एजीआई अंत नहीं है, बल्कि मानव विकास के इतिहास में एक नया प्रारंभिक बिंदु है। एजीआई की राह पर विचार करने के लिए कई चीजें हैं, और चीन का एआई उद्योग भी एक ताकत है जिसे नजरअंदाज नहीं किया जा सकता है।
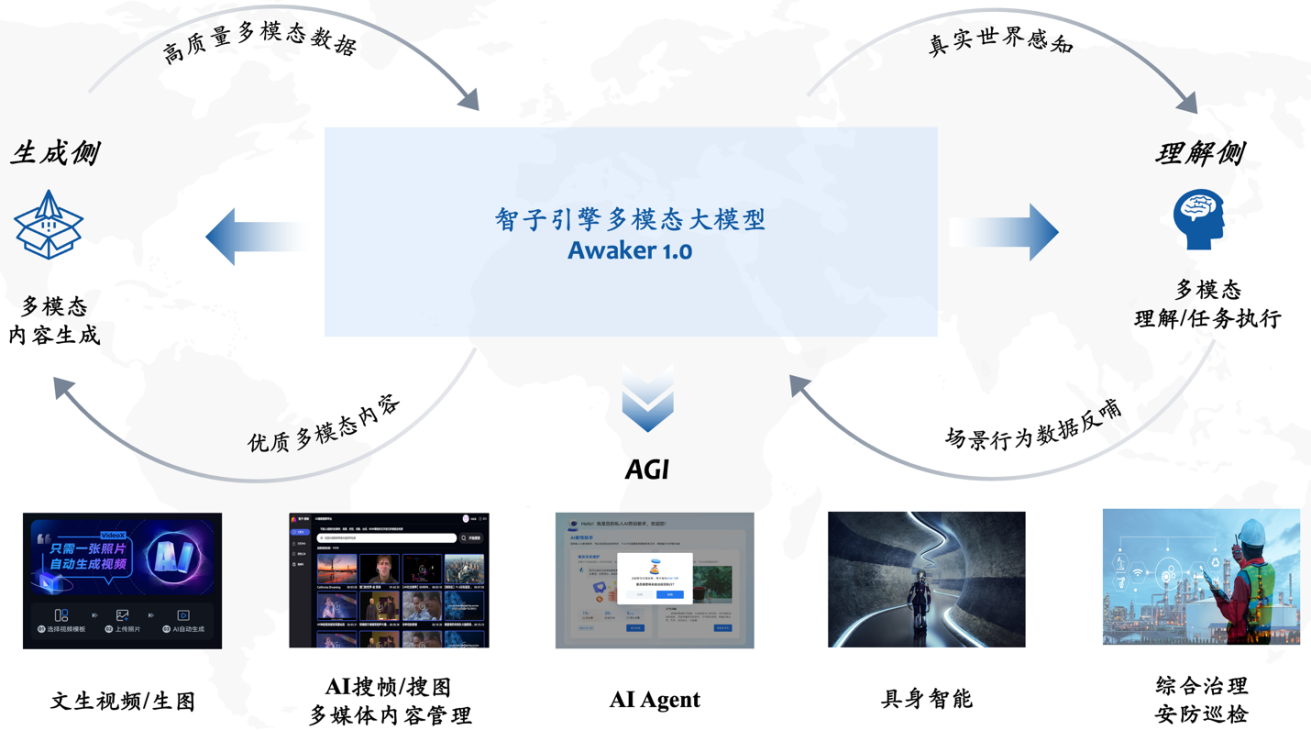
27 अप्रैल को आयोजित झोंगगुआनकुन फोरम जनरल आर्टिफिशियल इंटेलिजेंस पैरेलल फोरम में, चीन की रेनमिन यूनिवर्सिटी से संबद्ध स्टार्टअप कंपनी सोफॉन इंजन ने एजीआई की दिशा में एक महत्वपूर्ण कदम उठाते हुए एक नया मल्टी-मोडल बड़ा मॉडल अवेकर 1.0 जारी किया।
सोफॉन इंजन की पिछली पीढ़ी के ChatImg अनुक्रम मॉडल की तुलना में, Awaker 1.0 एक नए MOE आर्किटेक्चर को अपनाता है और इसमें स्वतंत्र अद्यतन क्षमताएं हैं। यह "सही" स्वतंत्र अद्यतन प्राप्त करने वाला उद्योग का पहला मल्टी-मोडल बड़ा मॉडल है। विज़ुअल जेनरेशन के संदर्भ में, अवेकर 1.0 पूरी तरह से स्व-विकसित वीडियो जेनरेशन बेस वीडीटी का उपयोग करता है, जो फोटो वीडियो जेनरेशन में सोरा की तुलना में बेहतर परिणाम प्राप्त करता है, बड़े मॉडलों को उतारने की "अंतिम मील" कठिनाई को तोड़ देता है।

अवेकर का MOE बेस मॉडल
समझ के पक्ष में, अवेकर 1.0 का बेस मॉडल मुख्य रूप से मल्टी-मोडल और मल्टी-टास्क प्री-ट्रेनिंग में गंभीर संघर्षों की समस्या को हल करता है। सावधानीपूर्वक डिज़ाइन किए गए मल्टी-टास्क एमओई आर्किटेक्चर से लाभ उठाते हुए, अवेकर 1.0 का बेस मॉडल न केवल सोफॉन इंजन की पिछली पीढ़ी के मल्टी-मोडल बड़े मॉडल ChatImg की बुनियादी क्षमताओं को प्राप्त कर सकता है, बल्कि प्रत्येक मल्टी-मोडल कार्य के लिए आवश्यक अद्वितीय क्षमताओं को भी सीख सकता है। . पिछली पीढ़ी के मल्टी-मोडल बड़े मॉडल ChatImg की तुलना में, कई कार्यों में Awaker 1.0 की बेस मॉडल क्षमताओं में काफी सुधार किया गया है।
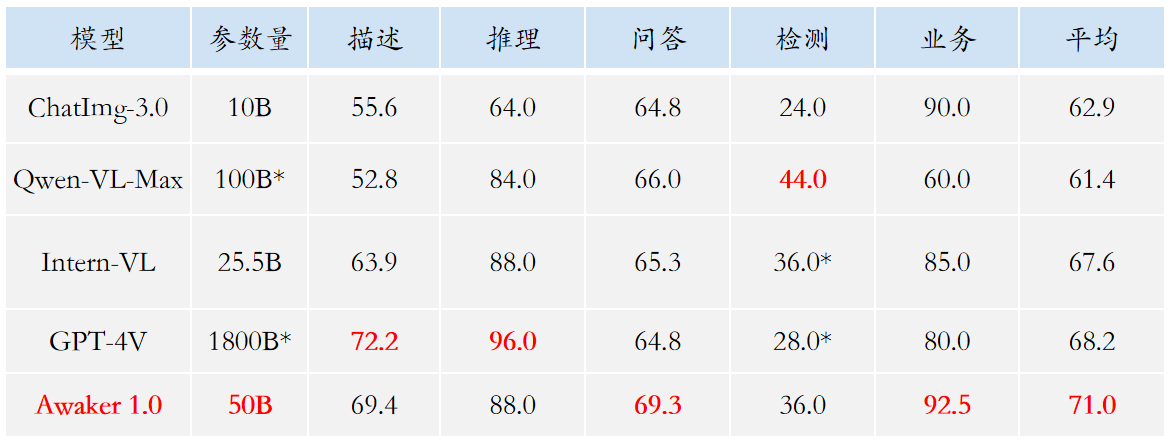
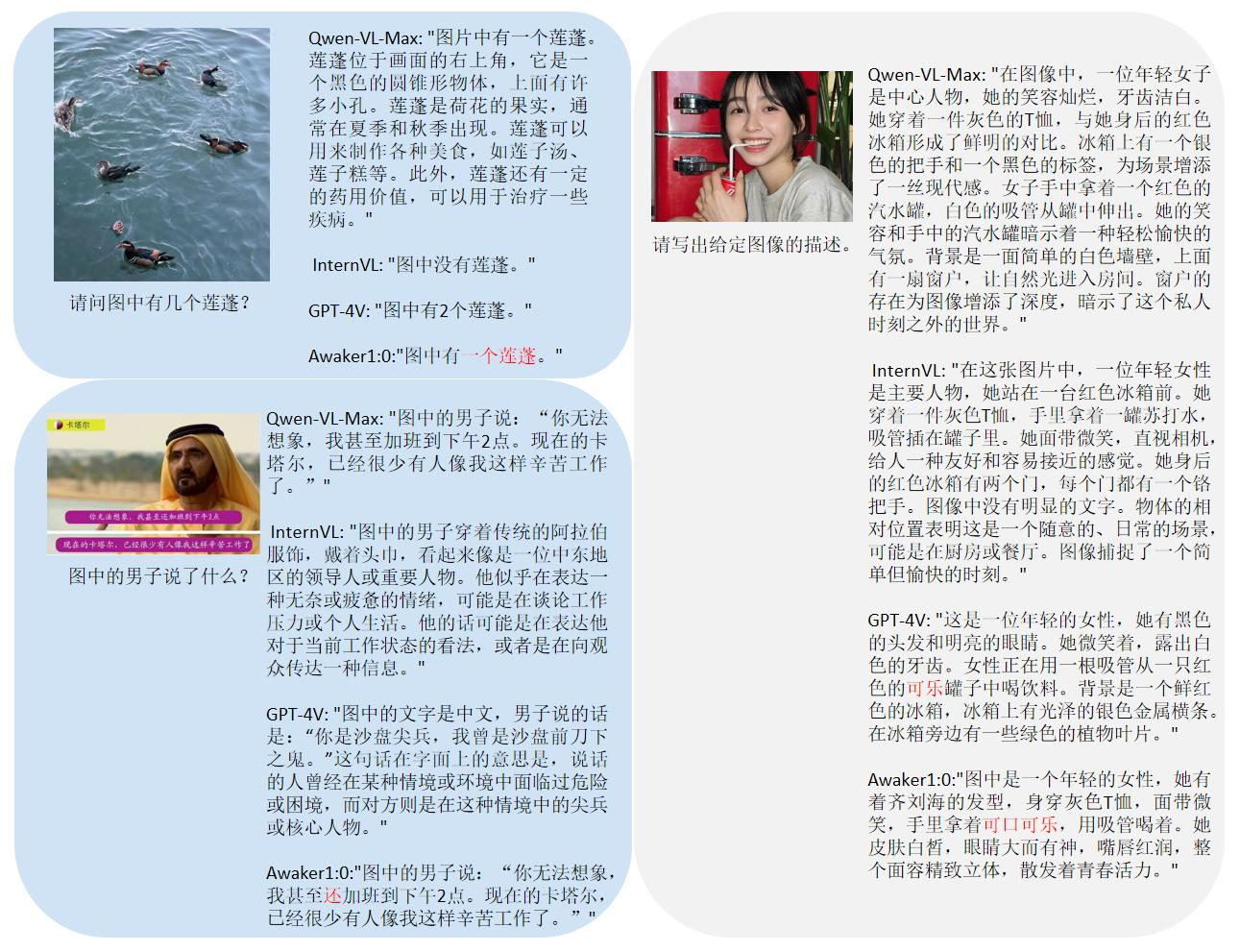
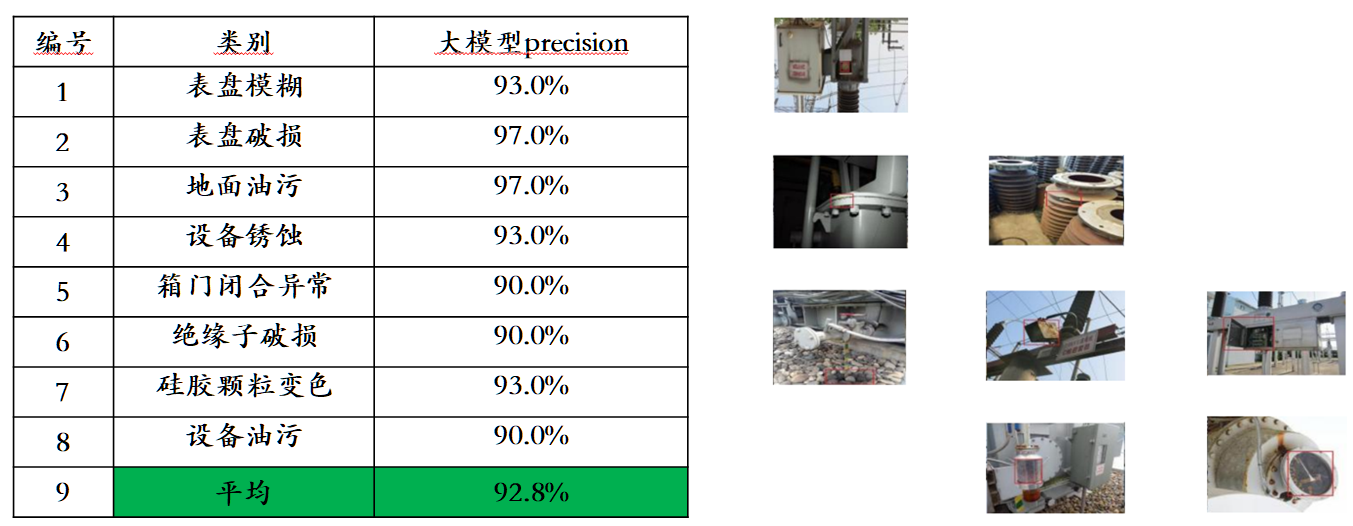
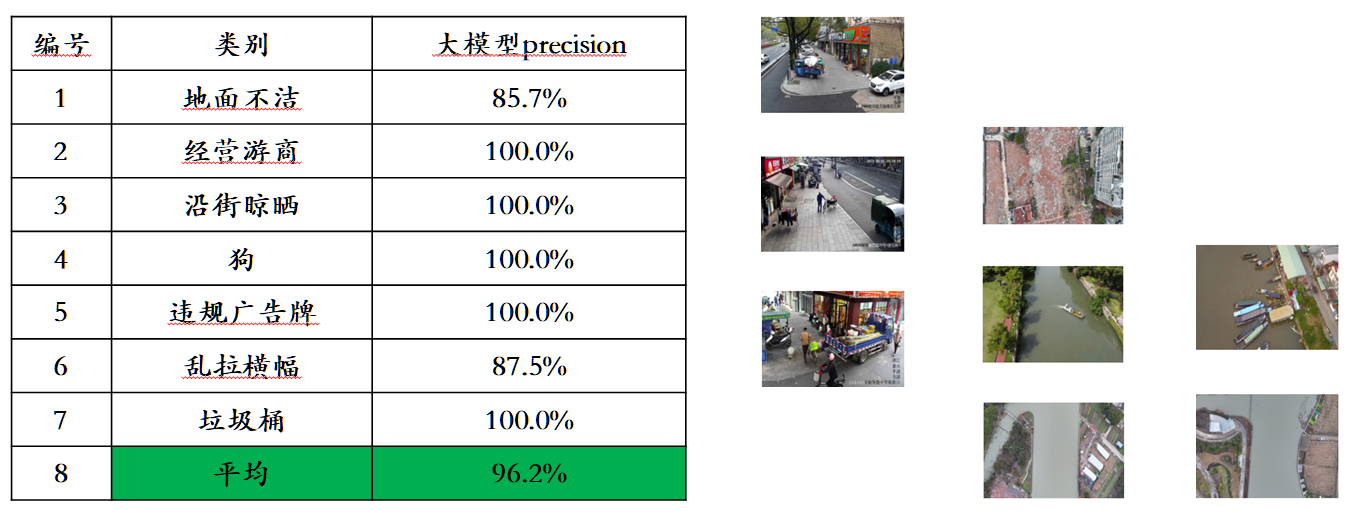
मुख्यधारा की मल्टी-मोडल मूल्यांकन सूचियों में मूल्यांकन डेटा रिसाव की समस्या को देखते हुए, सोफॉन इंजन ने अपना स्वयं का मूल्यांकन सेट बनाने के लिए एक सख्त मानक का खुलासा किया, जिसमें अधिकांश परीक्षण चित्र व्यक्तिगत मोबाइल फोन एल्बम से आते हैं। इस मल्टी-मोडल मूल्यांकन सेट में, यह अवेकर 1.0 और देश और विदेश में तीन सबसे उन्नत मल्टी-मोडल बड़े मॉडल पर निष्पक्ष मैनुअल मूल्यांकन करता है। विस्तृत मूल्यांकन परिणाम नीचे दी गई तालिका में दिखाए गए हैं। ध्यान दें कि GPT-4V और इंटर्न-वीएल सीधे तौर पर पहचान कार्यों का समर्थन नहीं करते हैं। उनके पहचान परिणाम मॉडल को ऑब्जेक्ट ओरिएंटेशन का वर्णन करने के लिए भाषा का उपयोग करने की आवश्यकता के द्वारा प्राप्त किए जाते हैं।
जागृत + सन्निहित बुद्धिमत्ता: एजीआई की ओर
मल्टी-मोडल बड़े मॉडल और सन्निहित बुद्धिमत्ता का संयोजन बहुत स्वाभाविक है, क्योंकि मल्टी-मोडल बड़े मॉडल की दृश्य समझ क्षमताओं को स्वाभाविक रूप से सन्निहित बुद्धिमान कैमरों के साथ जोड़ा जा सकता है। कृत्रिम बुद्धिमत्ता के क्षेत्र में, "मल्टी-मॉडल बड़े मॉडल + सन्निहित बुद्धिमत्ता" को सामान्य कृत्रिम बुद्धिमत्ता (एजीआई) प्राप्त करने के लिए एक व्यवहार्य मार्ग भी माना जाता है।
एक ओर, लोग सन्निहित बुद्धिमत्ता के अनुकूलनीय होने की अपेक्षा करते हैं, अर्थात्, एजेंट निरंतर सीखने के माध्यम से बदलते अनुप्रयोग वातावरण के अनुकूल हो सकता है, यह न केवल ज्ञात मल्टी-मोडल कार्यों पर बेहतर और बेहतर प्रदर्शन कर सकता है, बल्कि अज्ञात मल्टी के लिए भी जल्दी से अनुकूल हो सकता है -मोडल कार्य. दूसरी ओर, लोग यह भी उम्मीद करते हैं कि सन्निहित बुद्धिमत्ता वास्तव में रचनात्मक हो, यह आशा करते हुए कि यह नई रणनीतियों और समाधानों की खोज कर सकती है और पर्यावरण की स्वायत्त खोज के माध्यम से कृत्रिम बुद्धिमत्ता क्षमताओं की सीमाओं का पता लगा सकती है। सन्निहित बुद्धि के "मस्तिष्क" के रूप में बड़े मल्टी-मोडल मॉडल का उपयोग करके, सन्निहित बुद्धि की अनुकूलनशीलता और रचनात्मकता में काफी सुधार करना संभव है, जिससे अंततः एजीआई की दहलीज तक पहुंच सकता है (या यहां तक कि एजीआई प्राप्त कर सकता है)।
हालाँकि, मौजूदा बड़े मल्टी-मोडल मॉडल के साथ दो स्पष्ट समस्याएं हैं: पहला, मॉडल का पुनरावृत्त अद्यतन चक्र लंबा है, जिसके लिए बहुत अधिक मानव और वित्तीय निवेश की आवश्यकता होती है, दूसरा, मॉडल का प्रशिक्षण डेटा सभी मौजूदा डेटा से प्राप्त होता है; , और मॉडल लगातार बड़ी मात्रा में नया ज्ञान प्राप्त करने में असमर्थ है। यद्यपि निरंतर नए ज्ञान को आरएजी और लंबे संदर्भ के माध्यम से भी इंजेक्ट किया जा सकता है, मल्टी-मोडल बड़े मॉडल स्वयं इन नए ज्ञान को नहीं सीखते हैं, और ये दो उपचार विधियां अतिरिक्त समस्याएं भी लाएँगी। संक्षेप में, मौजूदा बड़े मल्टी-मॉडल मॉडल वास्तविक अनुप्रयोग परिदृश्यों में बहुत अनुकूलनीय नहीं हैं, रचनात्मक तो दूर की बात है, जिसके परिणामस्वरूप उद्योग में लागू होने पर विभिन्न कठिनाइयां पैदा होती हैं।
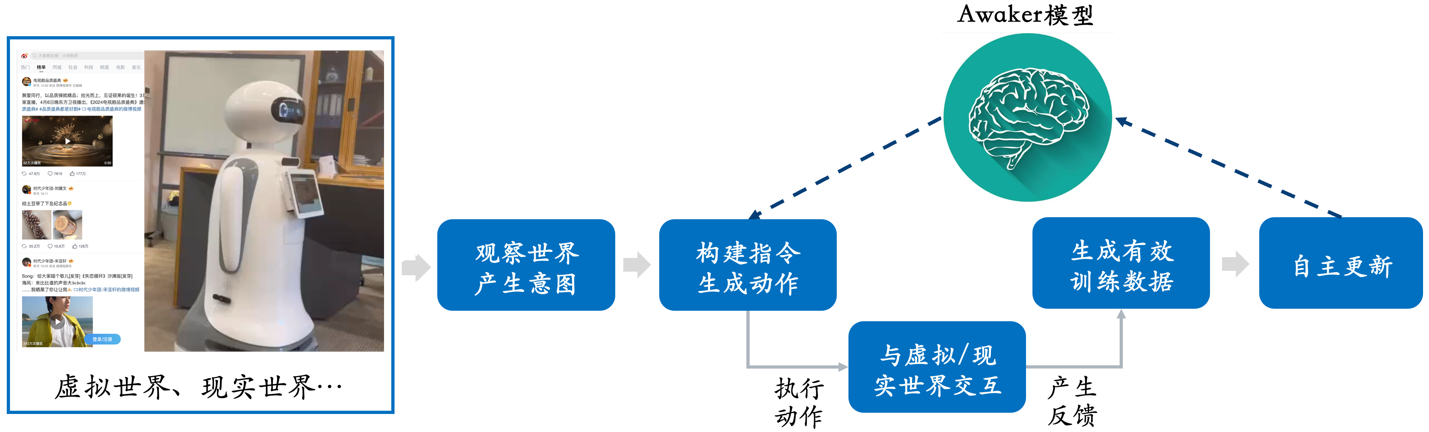
इस बार सोफॉन इंजन द्वारा जारी अवेकर 1.0 एक स्वायत्त अद्यतन तंत्र के साथ दुनिया का पहला मल्टी-मोडल बड़ा मॉडल है, जिसका उपयोग सन्निहित बुद्धिमत्ता के "मस्तिष्क" के रूप में किया जा सकता है। अवेकर 1.0 के स्वायत्त अद्यतन तंत्र में तीन प्रमुख प्रौद्योगिकियाँ शामिल हैं: सक्रिय डेटा उत्पादन, मॉडल प्रतिबिंब और मूल्यांकन, और निरंतर मॉडल अद्यतन।
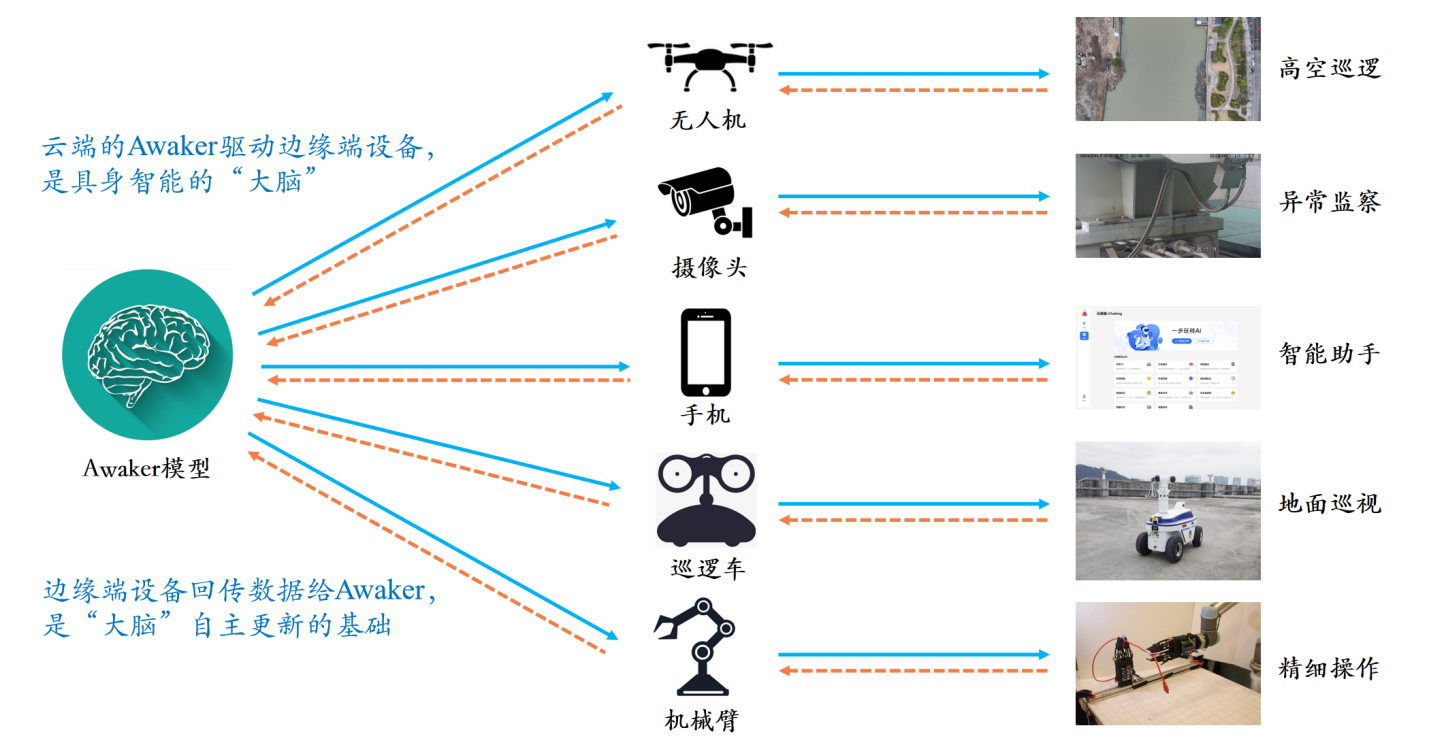
अन्य सभी बड़े मल्टी-मोडल मॉडलों से अलग, अवेकर 1.0 "लाइव" है और इसके मापदंडों को वास्तविक समय में लगातार अपडेट किया जा सकता है। जैसा कि ऊपर दिए गए फ्रेम आरेख से देखा जा सकता है, अवेकर 1.0 को विभिन्न स्मार्ट उपकरणों के साथ जोड़ा जा सकता है, स्मार्ट उपकरणों के माध्यम से दुनिया का निरीक्षण किया जा सकता है, कार्रवाई के इरादे उत्पन्न किए जा सकते हैं, और विभिन्न कार्यों को पूरा करने के लिए स्मार्ट उपकरणों को नियंत्रित करने के लिए स्वचालित रूप से निर्देश तैयार किए जा सकते हैं। स्मार्ट डिवाइस विभिन्न कार्यों को पूरा करने के बाद स्वचालित रूप से विभिन्न फीडबैक उत्पन्न करेंगे, निरंतर स्व-अद्यतन के लिए इन कार्यों और फीडबैक से प्रभावी प्रशिक्षण डेटा प्राप्त कर सकते हैं, और मॉडल की विभिन्न क्षमताओं को लगातार मजबूत कर सकते हैं।
एक उदाहरण के रूप में नए ज्ञान इंजेक्शन को लेते हुए, अवेकर 1.0 लगातार इंटरनेट पर नवीनतम समाचार जानकारी सीख सकता है और नई सीखी गई समाचार जानकारी के आधार पर विभिन्न जटिल प्रश्नों का उत्तर दे सकता है। RAG और लंबे संदर्भ के पारंपरिक तरीकों से अलग, Awaker 1.0 वास्तव में नया ज्ञान सीख सकता है और मॉडल के मापदंडों पर इसे "याद" कर सकता है।

जैसा कि उपरोक्त उदाहरण से देखा जा सकता है, लगातार तीन दिनों के सेल्फ-अपडेटिंग के दौरान, अवेकर 1.0 हर दिन दिन की समाचार जानकारी जानने और प्रश्नों का उत्तर देते समय संबंधित जानकारी को सटीक रूप से बोलने में सक्षम था। साथ ही, Awaker 1.0 निरंतर सीखने की प्रक्रिया के दौरान सीखे गए ज्ञान को नहीं भूलेगा। उदाहरण के लिए, Zhijie S7 का ज्ञान Awaker 1.0 द्वारा 2 दिनों के बाद भी याद या समझा जाता है।
क्लाउड-एज सहयोग प्राप्त करने के लिए अवेकर 1.0 को विभिन्न स्मार्ट उपकरणों के साथ भी जोड़ा जा सकता है। विभिन्न कार्यों को करने के लिए विभिन्न एज स्मार्ट उपकरणों को नियंत्रित करने के लिए अवेकर 1.0 को "मस्तिष्क" के रूप में क्लाउड में तैनात किया गया है। जब एज स्मार्ट डिवाइस विभिन्न कार्य करता है तो प्राप्त फीडबैक लगातार अवाकर 1.0 पर वापस प्रेषित किया जाएगा, जिससे यह लगातार प्रशिक्षण डेटा प्राप्त कर सकेगा और खुद को लगातार अपडेट कर सकेगा।
वास्तविक विश्व सिम्युलेटर: वीडीटी
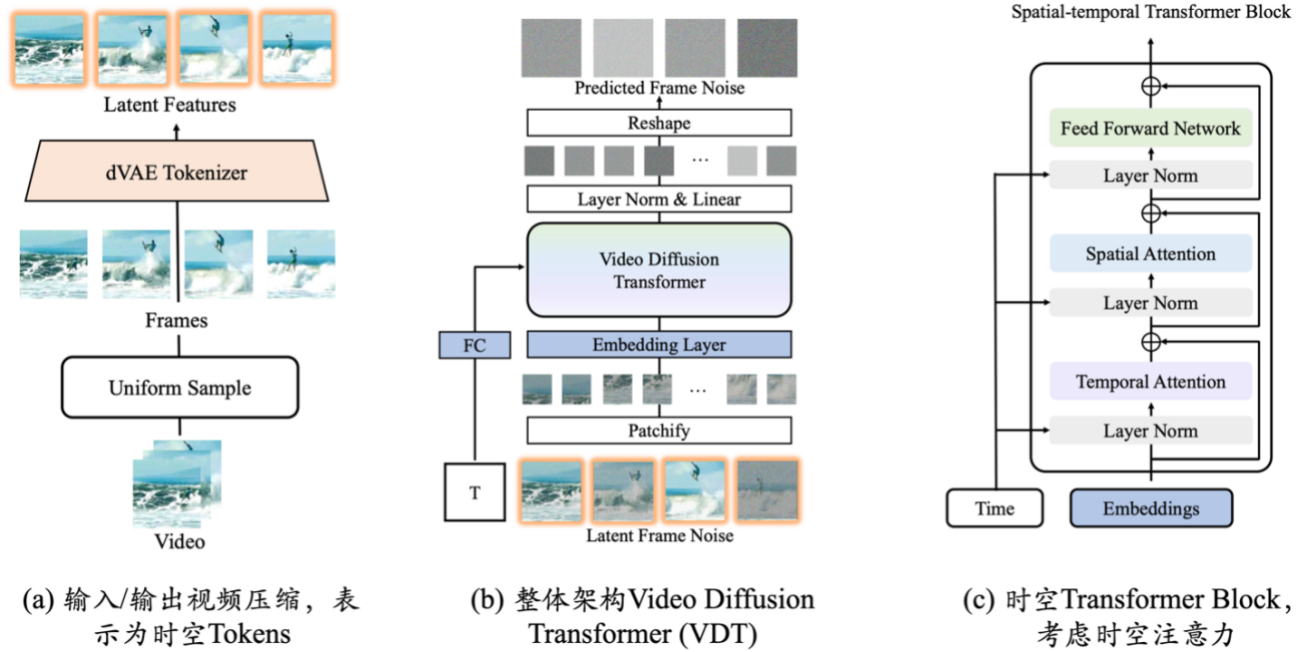
वीडियो जेनरेशन बेस वीडीटी के नवाचारों में मुख्य रूप से निम्नलिखित पहलू शामिल हैं:
- प्रसार-आधारित वीडियो पीढ़ी के लिए ट्रांसफार्मर तकनीक को लागू करना वीडियो पीढ़ी के क्षेत्र में ट्रांसफार्मर की महान क्षमता को प्रदर्शित करता है। वीडीटी का लाभ इसकी उत्कृष्ट समय-निर्भर कैप्चर क्षमता है, जो समय के साथ त्रि-आयामी वस्तुओं की भौतिक गतिशीलता का अनुकरण करने सहित अस्थायी रूप से सुसंगत वीडियो फ्रेम की पीढ़ी को सक्षम बनाता है।
- इस तकनीक के व्यापक अनुप्रयोग को साकार करते हुए, वीडीटी को विभिन्न प्रकार के वीडियो निर्माण कार्यों को संभालने में सक्षम बनाने के लिए एक एकीकृत स्पेटियोटेम्पोरल मास्क मॉडलिंग तंत्र का प्रस्ताव किया गया है। वीडीटी की लचीली सशर्त सूचना प्रसंस्करण विधियां, जैसे कि सरल टोकन स्पेस स्प्लिसिंग, विभिन्न लंबाई और तौर-तरीकों की जानकारी को प्रभावी ढंग से एकीकृत करती हैं। साथ ही, स्पेटियोटेम्पोरल मास्क मॉडलिंग तंत्र के साथ संयोजन करके, वीडीटी एक सार्वभौमिक वीडियो प्रसार उपकरण बन गया है, जिसे बिना शर्त पीढ़ी, वीडियो के बाद के फ्रेम भविष्यवाणी, फ्रेम इंटरपोलेशन, चित्र-जनरेटिंग वीडियो और वीडियो फ्रेम को संशोधित किए बिना लागू किया जा सकता है। मॉडल संरचना। समापन और अन्य वीडियो निर्माण कार्य।
सोफॉन इंजन टीम ने वीडीटी के सरल भौतिक कानूनों के अनुकरण की खोज पर ध्यान केंद्रित किया और फिज़न डेटा सेट पर वीडीटी को प्रशिक्षित किया। निम्नलिखित उदाहरण में, हमने पाया कि वीडीटी ने भौतिक प्रक्रियाओं का सफलतापूर्वक अनुकरण किया, जैसे कि गेंद का परवलयिक प्रक्षेपवक्र के साथ चलना और गेंद का एक विमान पर लुढ़कना और अन्य वस्तुओं से टकराना। साथ ही, पंक्ति 2 में दूसरे उदाहरण से यह भी देखा जा सकता है कि वीडीटी ने गेंद की गति और गति को पकड़ लिया, क्योंकि गेंद अंततः अपर्याप्त प्रभाव बल के कारण खंभे से नीचे नहीं गिरी। इससे साबित होता है कि ट्रांसफार्मर आर्किटेक्चर कुछ भौतिक नियम सीख सकता है।

उन्होंने फोटो वीडियो निर्माण कार्य पर भी गहन अन्वेषण किया। इस कार्य में वीडियो निर्माण की गुणवत्ता पर बहुत अधिक आवश्यकताएं हैं, क्योंकि हम स्वाभाविक रूप से चेहरों और पात्रों में गतिशील परिवर्तनों के प्रति अधिक संवेदनशील हैं। इस कार्य की विशिष्टता को देखते हुए, शोधकर्ताओं को फोटो वीडियो निर्माण की चुनौतियों से निपटने के लिए वीडीटी (या सोरा) और नियंत्रणीय पीढ़ी को संयोजित करने की आवश्यकता है। वर्तमान में, सोफ़ोन इंजन ने फोटो वीडियो पीढ़ी की अधिकांश प्रमुख तकनीकों को तोड़ दिया है और सोरा की तुलना में बेहतर फोटो वीडियो पीढ़ी गुणवत्ता हासिल की है। सोफ़ोन इंजन पोर्ट्रेट के नियंत्रणीय पीढ़ी एल्गोरिदम को अनुकूलित करना जारी रखेगा, और सक्रिय रूप से व्यावसायीकरण की खोज भी कर रहा है। वर्तमान में, एक पुष्टिकृत वाणिज्यिक लैंडिंग परिदृश्य पाया गया है, और निकट भविष्य में "अंतिम मील" में बड़े मॉडलों को उतारने की कठिनाई को तोड़ने की उम्मीद है।
भविष्य में, एक अधिक बहुमुखी वीडीटी मल्टी-मोडल बड़े मॉडल डेटा स्रोतों की समस्या को हल करने के लिए एक शक्तिशाली उपकरण बन जाएगा। वीडियो पीढ़ी का उपयोग करके, वीडीटी वास्तविक दुनिया का अनुकरण करने में सक्षम होगा, दृश्य डेटा उत्पादन की दक्षता में और सुधार करेगा, और मल्टी-मोडल बड़े मॉडल अवेकर के स्वतंत्र अपडेट के लिए सहायता प्रदान करेगा।
निष्कर्ष
सोफॉन इंजन टीम के लिए "एजीआई को साकार करने" के अंतिम लक्ष्य की ओर बढ़ने के लिए अवेकर 1.0 एक महत्वपूर्ण कदम है। सोफॉन इंजन ने एपीपीएसओ को बताया कि टीम का मानना है कि एआई की आत्म-अन्वेषण, आत्म-प्रतिबिंब और अन्य स्वायत्त सीखने की क्षमताएं खुफिया स्तर के लिए महत्वपूर्ण मूल्यांकन मानदंड हैं, और पैरामीटर स्केल (स्केलिंग कानून) में निरंतर वृद्धि के समान ही महत्वपूर्ण हैं।
अवेकर 1.0 ने "सक्रिय डेटा पीढ़ी, मॉडल प्रतिबिंब और मूल्यांकन, और निरंतर मॉडल अपडेट" जैसे प्रमुख तकनीकी ढांचे को लागू किया है, जिससे समझ पक्ष और पीढ़ी पक्ष दोनों पर सफलता प्राप्त हुई है। इससे मल्टी-मोडल बड़े के विकास में तेजी आने की उम्मीद है मॉडल उद्योग और अंततः मनुष्यों को एजीआई का एहसास करने की अनुमति देता है।
# aifaner के आधिकारिक WeChat सार्वजनिक खाते का अनुसरण करने के लिए आपका स्वागत है: aifaner (WeChat ID: ifanr) आपको जल्द से जल्द अधिक रोमांचक सामग्री प्रदान की जाएगी।