
पिछले हफ्ते, OpenAI ने देर रात एक बड़ा कदम जारी करने का बीड़ा उठाया, लॉन्च किए गए GPT-4o मिनी ने "बड़े को छोटे से हराने" का अच्छा प्रदर्शन किया, GPT-3.5 टर्बो को "रिटायरमेंट" में धकेल दिया, और यहां तक कि उससे भी आगे निकल गया। इसने बड़े मॉडल क्षेत्र एलएमएसवाईएस में जीपीटी-4 उत्तीर्ण किया।
इस सप्ताह मेटा द्वारा जारी किए गए लामा 3.1 बड़े मॉडल के लिए, यदि पहले सोपानक का 405बी आकार अभी भी अपेक्षित है, तो 8बी और 70बी आकार के संस्करण जो "बड़े पर छोटी जीत" करते हैं, अधिक आश्चर्य लाते हैं।
और यह छोटे मॉडल प्रतियोगिता का अंत नहीं हो सकता है, बल्कि संभवतः एक नया शुरुआती बिंदु है।

ऐसा नहीं है कि बड़े मॉडल अप्राप्य हैं, लेकिन छोटे मॉडल अधिक लागत प्रभावी हैं
एआई सर्कल की विशाल दुनिया में, छोटे मॉडलों की हमेशा अपनी किंवदंतियाँ रही हैं।
बाहर देखने पर, पिछले साल के ब्लॉकबस्टर मिस्ट्रल 7बी को रिलीज़ होते ही "सर्वश्रेष्ठ 7बी मॉडल" के रूप में प्रतिष्ठित किया गया था, इसने कई मूल्यांकन बेंचमार्क में 13बी पैरामीटर मॉडल लामा 2 को हराया, और तर्क, गणित और कोड पीढ़ी में इसे पीछे छोड़ दिया .
इस वर्ष माइक्रोसॉफ्ट ने सबसे शक्तिशाली छोटे पैरामीटर बड़े मॉडल फाई-3-मिनी को भी ओपन सोर्स किया, हालांकि मापदंडों की संख्या केवल 3.8 बी है, प्रदर्शन मूल्यांकन परिणाम समान पैरामीटर स्केल के स्तर से कहीं अधिक हैं और बड़े मॉडल जैसे तुलनीय हैं। जीपीटी-3.5 और क्लाउड-3 सॉनेट।
अंदर देखने पर, वॉल इंटेलिजेंस ने फरवरी की शुरुआत में केवल 2बी मापदंडों के साथ एक साइड-टू-साइड भाषा मॉडल लॉन्च किया, यह मजबूत प्रदर्शन प्राप्त करने के लिए छोटे आकार का उपयोग करता है, इसका प्रदर्शन लोकप्रिय फ्रांसीसी मॉडल मिस्ट्रल -7 बी से बेहतर है। लिटिल स्टील"। बंदूक"।

कुछ समय पहले, MiniCPM-Llama3-V2.5, जिसका केवल 8B पैरामीटर आकार है, ने मल्टी-मोडल व्यापक प्रदर्शन और OCR क्षमताओं के मामले में GPT-4V और जेमिनी प्रो जैसे बड़े मॉडलों को पीछे छोड़ दिया था, इसलिए स्टैनफोर्ड द्वारा इसकी आलोचना की गई थी विश्वविद्यालय एआई टीम।
पिछले हफ्ते तक, ओपनएआई, जो देर रात तक बमबारी कर रहा था, ने इसे "सबसे शक्तिशाली और लागत प्रभावी छोटे पैरामीटर मॉडल" के रूप में वर्णित किया – जीपीटी -4o मिनी, जिसने सभी का ध्यान छोटे मॉडल पर वापस ला दिया।
चूँकि OpenAI ने दुनिया को जेनरेटिव AI की कल्पना में खींच लिया है, लंबे संदर्भों से लेकर रोलिंग पैरामीटर्स तक, एजेंटों तक और अब मूल्य युद्धों तक, देश और विदेश में विकास हमेशा एक तर्क के इर्द-गिर्द घूमता रहा है – व्यावसायीकरण की ओर बढ़ते हुए क्षेत्र में बने रहना कार्ड टेबल पर.
इसलिए, जनमत क्षेत्र में, सबसे ज्यादा ध्यान खींचने वाली बात यह है कि ओपनएआई, जिसने कीमतों में कटौती की है, मूल्य युद्ध में प्रवेश करता दिख रहा है।
कई लोगों को GPT-4o मिनी की कीमत का स्पष्ट अंदाजा नहीं होगा। GPT-4o मिनी की कीमत प्रति 1 मिलियन इनपुट टोकन पर 15 सेंट और प्रति 1 मिलियन आउटपुट टोकन पर 60 सेंट है, जो GPT-3.5 टर्बो से 60% से अधिक सस्ता है।
दूसरे शब्दों में, GPT-4o मिनी केवल 60 सेंट में 2500 पेज की किताब तैयार करता है।

ओपनएआई के सीईओ सैम ऑल्टमैन ने भी एक्स पर अफसोस जताया कि दो साल पहले के सबसे शक्तिशाली मॉडल जीपीटी-4ओ मिनी की तुलना में न केवल प्रदर्शन में भारी अंतर था, बल्कि उपयोग की लागत भी अब की तुलना में 100 गुना अधिक थी।
जबकि बड़े मॉडलों के लिए मूल्य युद्ध तेजी से भयंकर होता जा रहा है, कुछ कुशल और किफायती ओपन सोर्स छोटे मॉडल बाजार का ध्यान आकर्षित करने की अधिक संभावना रखते हैं, ऐसा नहीं है कि बड़े मॉडल का उपयोग नहीं किया जा सकता है, लेकिन छोटे मॉडल अधिक लागत प्रभावी हैं .
एक ओर, जब दुनिया भर में जीपीयू बिक चुके हैं या यहां तक कि स्टॉक से बाहर हैं, तो कम प्रशिक्षण और तैनाती लागत वाले छोटे ओपन सोर्स मॉडल धीरे-धीरे बढ़त हासिल करने के लिए पर्याप्त हैं।
उदाहरण के लिए, मियांबी इंटेलिजेंस द्वारा लॉन्च किया गया मिनीसीपीएम अपने छोटे मापदंडों के साथ अनुमान लागत में भारी गिरावट हासिल कर सकता है, और यहां तक कि सीपीयू अनुमान भी प्राप्त कर सकता है। इसके लिए निरंतर पैरामीटर प्रशिक्षण के लिए केवल एक मशीन और पैरामीटर फाइन-ट्यूनिंग के लिए एक ग्राफिक्स कार्ड की आवश्यकता होती है लागत स्थान में भी निरंतर सुधार हो रहे हैं।
यदि आप एक परिपक्व डेवलपर हैं, तो आप स्वयं एक छोटा मॉडल बनाकर कानूनी क्षेत्र में एक लंबवत मॉडल को प्रशिक्षित भी कर सकते हैं, और अनुमान लागत एक बड़े मॉडल को ठीक करने की लागत का केवल एक हजारवां हिस्सा हो सकती है।

कुछ टर्मिनल-साइड "छोटे मॉडल" अनुप्रयोगों के कार्यान्वयन ने कई निर्माताओं को लाभप्रदता की सुबह देखने की अनुमति दी है। उदाहरण के लिए, फेसवॉल इंटेलिजेंस ने शेन्ज़ेन इंटरमीडिएट पीपुल्स कोर्ट को एक कृत्रिम बुद्धिमत्ता-सहायता परीक्षण प्रणाली शुरू करने में मदद की, जिससे बाजार में प्रौद्योगिकी का मूल्य साबित हुआ।
बेशक, यह कहना अधिक सटीक है कि जो बदलाव हम देखना शुरू करेंगे वह बड़े मॉडल से छोटे मॉडल में बदलाव नहीं है, बल्कि मॉडल की एक श्रेणी से मॉडल के पोर्टफोलियो में बदलाव है, जिसमें सही मॉडल का चुनाव निर्भर करता है। संगठन की विशिष्ट आवश्यकताओं, कार्यों की जटिलता और उपलब्ध संसाधनों पर।
दूसरी ओर, छोटे मॉडलों को मोबाइल उपकरणों, एम्बेडेड सिस्टम या कम-शक्ति वाले वातावरण में तैनात करना और एकीकृत करना आसान होता है।
एक छोटे मॉडल का पैरामीटर स्केल बड़े मॉडल की तुलना में अपेक्षाकृत छोटा होता है, इसकी कंप्यूटिंग संसाधनों (जैसे एआई कंप्यूटिंग पावर, मेमोरी इत्यादि) की मांग कम होती है, और यह सीमित वाले एंड-साइड डिवाइस पर अधिक आसानी से चल सकता है। संसाधन। इसके अलावा, एंड-साइड उपकरण में आमतौर पर ऊर्जा खपत, गर्मी उत्पादन और अन्य मुद्दों के लिए अधिक चरम आवश्यकताएं होती हैं, विशेष रूप से डिज़ाइन किए गए छोटे मॉडल एंड-साइड उपकरण की सीमाओं को बेहतर ढंग से अनुकूलित कर सकते हैं।

ऑनर के सीईओ झाओ मिंग ने कहा कि क्लाइंट पक्ष पर एआई कंप्यूटिंग पावर मुद्दों के कारण, पैरामीटर 1बी और 10बी के बीच हो सकते हैं। बड़े नेटवर्क मॉडल की क्लाउड कंप्यूटिंग क्षमता 10-100 बिलियन या इससे भी अधिक तक पहुंच सकती है दो। ।
फ़ोन बहुत सीमित जगह में है, है ना? यह सीमित बैटरी, सीमित ताप अपव्यय और सीमित भंडारण वातावरण में 7 बिलियन का समर्थन करता है। यदि आप कल्पना करें कि इसमें बहुत सारी बाधाएँ हैं, तो यह सबसे कठिन होगा।
हमने ऐप्पल के स्मार्ट फोन के संचालन के लिए जिम्मेदार पर्दे के पीछे के नायकों का भी खुलासा किया है, उनमें से फाइन-ट्यून 3बी छोटा मॉडल एक एडाप्टर के आशीर्वाद के साथ सारांश और पॉलिशिंग जैसे कार्यों के लिए समर्पित है जेम्मा-7बी मोबाइल टर्मिनलों पर चलने के लिए उपयुक्त है। इसमें गूगल भी अगले कुछ महीनों में मोबाइल फोन टर्मिनलों के लिए उपयुक्त छोटे मॉडल जेम्मा-2 के 2बी संस्करण को अपडेट करने की योजना बना रहा है।

हाल ही में, पूर्व ओपनएआई गुरु आंद्रेज कारपैथी ने भी एक निर्णय दिया था कि मॉडल आकार में प्रतिस्पर्धा "रिवर्स इनवोलुशन" होगी, बड़ी और बड़ी नहीं होगी, बल्कि कौन छोटा और अधिक लचीला होगा।
छोटे मॉडल बड़े मॉडलों को छोटे मॉडलों से क्यों हरा सकते हैं?
आंद्रेज कारपैथी की भविष्यवाणी निराधार नहीं है।
इस डेटा-केंद्रित युग में, मॉडल तेजी से बड़े और अधिक जटिल होते जा रहे हैं। बड़े पैमाने पर डेटा पर प्रशिक्षित अधिकांश बड़े मॉडल (जैसे GPT-4) का उपयोग वास्तव में बड़ी संख्या में अप्रासंगिक विवरणों को याद रखने के लिए किया जाता है, यानी जानकारी को याद रखने के लिए। रटते हुए।
हालाँकि, सुव्यवस्थित मॉडल विशिष्ट कार्यों पर "छोटे के साथ बड़े को जीत" भी सकता है, और इसकी प्रयोज्यता कई "सुपर बड़े मॉडल" के बराबर है।
हगिंग फेस के सीईओ क्लेम डेलांगु ने यह भी सुझाव दिया है कि 99% तक उपयोग के मामलों को छोटे मॉडल का उपयोग करके हल किया जा सकता है, और भविष्यवाणी की है कि 2024 छोटे भाषा मॉडल का वर्ष होगा।
कारणों की जांच करने से पहले, हमें पहले कुछ विज्ञान ज्ञान को लोकप्रिय बनाना होगा।
2020 में, OpenAI ने एक पेपर में एक प्रसिद्ध कानून प्रस्तावित किया: स्केलिंग कानून, जिसका अर्थ है कि जैसे-जैसे मॉडल का आकार बढ़ेगा, इसका प्रदर्शन भी बढ़ेगा। जीपीटी-4 जैसे मॉडलों की शुरूआत के साथ, स्केलिंग कानून के फायदे धीरे-धीरे सामने आए हैं।
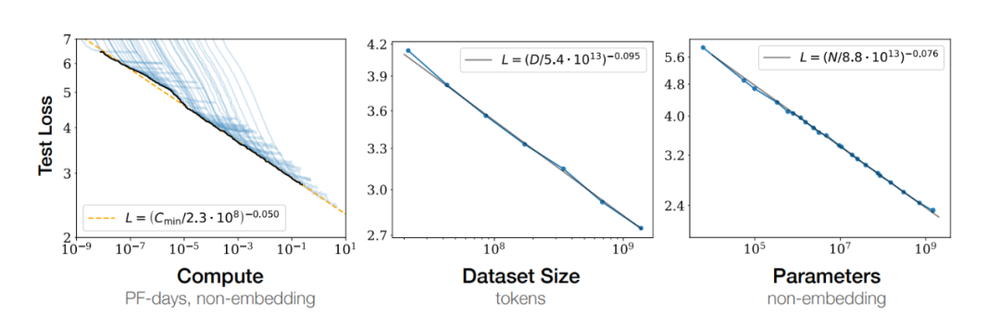
एआई के क्षेत्र में शोधकर्ताओं और इंजीनियरों का दृढ़ विश्वास है कि मॉडल के मापदंडों की संख्या बढ़ाकर, मॉडल की सीखने की क्षमता और सामान्यीकरण क्षमता में और सुधार किया जा सकता है। इस तरह, हमने मॉडल पैमाने को अरबों मापदंडों से सैकड़ों अरबों तक छलांग लगाते हुए देखा है, और यहां तक कि खरबों मापदंडों वाले मॉडल की ओर भी बढ़ते हुए देखा है।
एआई की दुनिया में, किसी मॉडल का आकार उसकी बुद्धिमत्ता को मापने का एकमात्र मानदंड नहीं है।
इसके विपरीत, एक अच्छी तरह से डिज़ाइन किया गया छोटा मॉडल, एल्गोरिदम को अनुकूलित करके, डेटा गुणवत्ता में सुधार करके और उन्नत संपीड़न तकनीक को अपनाकर, अक्सर विशिष्ट कार्यों पर एक बड़े मॉडल के बराबर या उससे भी बेहतर प्रदर्शन दिखा सकता है। बड़े परिणाम प्राप्त करने के लिए छोटे का उपयोग करने की यह रणनीति एआई के क्षेत्र में एक नया चलन बन रही है।
डेटा गुणवत्ता में सुधार करना छोटे मॉडलों के लिए बड़े मॉडलों पर जीत हासिल करने का एक तरीका है।
सीटीओ और कोलेससे के सह-संस्थापक, सतीश जयंती ने एक बार मॉडलों में डेटा की भूमिका का वर्णन किया था:
यदि एलएलएम 17वीं शताब्दी में अस्तित्व में था, और हमने चैटजीपीटी से पूछा कि क्या पृथ्वी गोल है या चपटी है, और उसने उत्तर दिया कि पृथ्वी चपटी है, ऐसा इसलिए होगा क्योंकि हमारे द्वारा प्रदान किए गए डेटा ने उसे आश्वस्त किया कि यह सच था। हम एलएलएम को जो डेटा प्रदान करते हैं और हम उसे कैसे प्रशिक्षित करते हैं, वह सीधे उसके आउटपुट को प्रभावित करेगा।
उच्च-गुणवत्ता वाले परिणाम उत्पन्न करने के लिए, बड़े भाषा मॉडलों को विशिष्ट विषयों और डोमेन के लिए उच्च-गुणवत्ता, लक्षित डेटा पर प्रशिक्षित करने की आवश्यकता होती है। जिस तरह छात्रों को सीखने के लिए गुणवत्तापूर्ण पाठ्यपुस्तकों की आवश्यकता होती है, उसी तरह एलएलएम को भी गुणवत्तापूर्ण डेटा स्रोतों की आवश्यकता होती है।

चमत्कार हासिल करने के लिए कड़ी मेहनत करने के पारंपरिक हिंसक सौंदर्य को त्यागते हुए, सिंघुआ विश्वविद्यालय में कंप्यूटर विज्ञान विभाग में स्थायी एसोसिएट प्रोफेसर और वॉल-फेसिंग इंटेलिजेंस के मुख्य वैज्ञानिक लियू झियुआन ने हाल ही में बड़े युग में वॉल-फेसिंग कानून का प्रस्ताव रखा है। मॉडल, यानी मॉडल का ज्ञान घनत्व लगातार बढ़ रहा है, औसतन हर आठ महीने में दोगुना हो रहा है।
उनमें से, ज्ञान घनत्व = मॉडल क्षमता/गणना में शामिल मॉडल पैरामीटर।
लियू ज़ियुआन ने स्पष्ट रूप से समझाया कि यदि आपको 100 आईक्यू परीक्षण प्रश्न दिए जाते हैं, तो आपका स्कोर न केवल इस पर निर्भर करेगा कि आप कितने प्रश्नों का सही उत्तर देते हैं, बल्कि इस पर भी निर्भर करेगा कि आप इन प्रश्नों को पूरा करने के लिए कितने न्यूरॉन्स का उपयोग करते हैं। आप जितने अधिक कार्य कम न्यूरॉन्स के साथ करेंगे, आपका आईक्यू उतना ही अधिक होगा।
यह बिल्कुल मूल विचार है जो ज्ञान घनत्व बताता है:
इसके दो तत्व हैं एक तत्व इस मॉडल की क्षमता है। दूसरा तत्व इस क्षमता के लिए आवश्यक न्यूरॉन्स की संख्या या संबंधित कंप्यूटिंग पावर खपत है।
2020 में OpenAI द्वारा जारी 175 बिलियन पैरामीटर GPT-3 की तुलना में, 2024 में इसने समान प्रदर्शन के साथ MiniCPM-2.4B जारी किया, लेकिन GPT-3 के रूप में केवल 2.4 बिलियन पैरामीटर, जिसने ज्ञान घनत्व को लगभग 86 गुना बढ़ा दिया।
टोरंटो विश्वविद्यालय के एक अध्ययन से यह भी पता चलता है कि सभी डेटा आवश्यक नहीं हैं, बड़े डेटा सेट से उच्च-गुणवत्ता वाले उप-समूह की पहचान करना आवश्यक है जो मूल डेटा सेट में सभी जानकारी और विविधता को संसाधित करना और बनाए रखना आसान है।
भले ही 95% तक प्रशिक्षण डेटा हटा दिया जाए, एक विशिष्ट वितरण के भीतर मॉडल का पूर्वानुमानित प्रदर्शन महत्वपूर्ण रूप से प्रभावित नहीं हो सकता है।

सबसे ताज़ा उदाहरण मेटा लामा 3.1 बड़ा मॉडल है।
जब मेटा ने लामा 3 को प्रशिक्षित किया, तो उसने 15टी टोकन प्रशिक्षण डेटा खिलाया, लेकिन लामा2 और लामा3 के प्रशिक्षण के बाद के काम के लिए जिम्मेदार मेटा एआई शोधकर्ता थॉमस स्कियालोम ने कहा: इंटरनेट पर पाठ बेकार जानकारी से भरा है, और प्रशिक्षण पर आधारित है यह जानकारी कंप्यूटिंग संसाधनों की बर्बादी है।
"लामा 3 के बाद के प्रशिक्षण में कोई मैन्युअल रूप से लिखित उत्तर नहीं हैं… यह केवल लामा 2 से विशुद्ध रूप से सिंथेटिक डेटा का उपयोग करता है।"
इसके अलावा, ज्ञान आसवन भी "छोटे से बड़े पर विजय पाने" की महत्वपूर्ण विधियों में से एक है।
ज्ञान आसवन एक छोटे और सरल "छात्र मॉडल" के प्रशिक्षण का मार्गदर्शन करने के लिए एक बड़े और जटिल "शिक्षक मॉडल" का उपयोग करने को संदर्भित करता है, जो बड़े मॉडल के शक्तिशाली प्रदर्शन और बेहतर सामान्यीकरण क्षमता को अधिक हल्के, कम्प्यूटेशनल छोटे मॉडल में स्थानांतरित कर सकता है जिसकी लागत होती है कम।

लामा 3.1 के रिलीज़ होने के बाद, मेटा के सीईओ जुकरबर्ग ने एक लंबा लेख "ओपन सोर्स एआई इज़ द पाथ फॉरवर्ड" लिखा, जिसमें उन्होंने छोटे मॉडलों को फाइन-ट्यूनिंग और डिस्टिलिंग के महत्व पर भी प्रकाश डाला।
हमें अपने स्वयं के मॉडलों को प्रशिक्षित करने, बेहतर बनाने और विकसित करने की आवश्यकता है। प्रत्येक संगठन की अलग-अलग ज़रूरतें होती हैं जिन्हें अलग-अलग पैमाने पर और विशिष्ट डेटा के साथ प्रशिक्षित या ठीक-ठीक मॉडल का उपयोग करके पूरा किया जाता है।
ऑन-डिवाइस कार्यों और वर्गीकरण कार्यों के लिए छोटे मॉडल की आवश्यकता होती है, जबकि अधिक जटिल कार्यों के लिए बड़े मॉडल की आवश्यकता होती है।
अब आप अत्याधुनिक लामा मॉडल ले सकते हैं, उन्हें अपने डेटा पर प्रशिक्षित करना जारी रख सकते हैं, और फिर उन्हें उस मॉडल आकार में डिस्टिल कर सकते हैं जो आपकी आवश्यकताओं के लिए सबसे उपयुक्त है – हमारे या किसी और के डेटा को देखे बिना।
उद्योग में आम तौर पर यह भी माना जाता है कि मेटा लामा 3.1 के 8बी और 70बी संस्करण अल्ट्रा-बड़े कप से आसवित हैं, इसलिए समग्र प्रदर्शन में काफी सुधार हुआ है और मॉडल दक्षता भी अधिक है।
या, मॉडल आर्किटेक्चर अनुकूलन भी महत्वपूर्ण है, उदाहरण के लिए, मोबाइलनेट डिज़ाइन का मूल उद्देश्य मोबाइल उपकरणों पर कुशल गहन शिक्षण मॉडल लागू करना है।
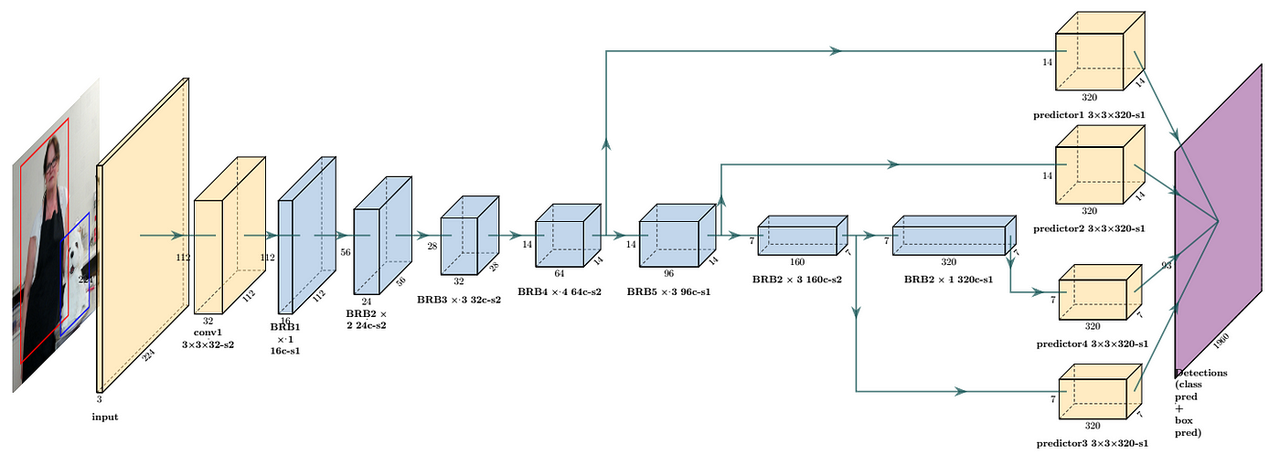
यह गहराई से अलग करने योग्य कनवल्शन के माध्यम से मॉडल के मापदंडों की संख्या को काफी कम कर देता है। ResNet की तुलना में, MobileNetV1 मापदंडों की संख्या को लगभग 8-9 गुना कम कर देता है।
पैरामीटरों की कम संख्या के कारण मोबाइलनेट कम्प्यूटेशनल रूप से अधिक कुशल है। यह मोबाइल उपकरणों जैसे संसाधन-बाधित वातावरणों के लिए विशेष रूप से महत्वपूर्ण है, क्योंकि यह बहुत अधिक प्रदर्शन का त्याग किए बिना गणना और भंडारण आवश्यकताओं को काफी कम कर सकता है।
तकनीकी स्तर पर हुई प्रगति के बावजूद, एआई उद्योग अभी भी दीर्घकालिक निवेश और उच्च लागत की चुनौती का सामना कर रहा है, और रिटर्न चक्र अपेक्षाकृत लंबा है।
"डेली इकोनॉमिक न्यूज़" के अधूरे आँकड़ों के अनुसार, इस साल अप्रैल के अंत तक, चीन में कुल लगभग 305 बड़े मॉडल लॉन्च किए गए थे, लेकिन 16 मई तक, अभी भी लगभग 165 बड़े मॉडल थे जो अभी तक लॉन्च नहीं हुए थे। पूरा पंजीकरण.
Baidu के संस्थापक रॉबिन ली ने सार्वजनिक रूप से आलोचना की है कि कई मौजूदा बुनियादी मॉडलों का अस्तित्व संसाधनों की बर्बादी है, और सुझाव दिया है कि उद्योगों के साथ मॉडल के संयोजन की संभावना का पता लगाने और अगले संभावित सुपर एप्लिकेशन को विकसित करने के लिए संसाधनों का अधिक उपयोग किया जाना चाहिए।

वर्तमान एआई उद्योग में यह भी एक मुख्य मुद्दा है, मॉडलों की संख्या में वृद्धि और व्यावहारिक अनुप्रयोगों के कार्यान्वयन के बीच असंगत विरोधाभास।
इस चुनौती का सामना करते हुए, उद्योग का ध्यान धीरे-धीरे एआई प्रौद्योगिकी के अनुप्रयोग में तेजी लाने पर केंद्रित हो गया है, और कम तैनाती लागत और उच्च दक्षता वाले छोटे मॉडल अधिक उपयुक्त सफलता बिंदु बन गए हैं।
इसलिए हमने देखा कि विशिष्ट क्षेत्रों पर ध्यान केंद्रित करने वाले कुछ छोटे मॉडल उभरने लगे, जैसे खाना पकाने के लिए बड़े मॉडल और लाइव स्ट्रीमिंग के लिए बड़े मॉडल। हालाँकि ये नाम थोड़े भ्रामक लग सकते हैं, ये बिल्कुल सही रास्ते पर हैं।
संक्षेप में, भविष्य में एआई अब एक एकल, विशाल अस्तित्व नहीं रहेगा, बल्कि अधिक विविध और वैयक्तिकृत होगा। छोटे मॉडलों का उदय इसी प्रवृत्ति का प्रतिबिंब है। विशिष्ट कार्यों पर उनका उत्कृष्ट प्रदर्शन साबित करता है कि "छोटी लेकिन सुंदर" भी सम्मान और पहचान जीत सकती है।
एक और बात
यदि आप इस मॉडल को अपने iPhone पर पहले से चलाना चाहते हैं, तो आप हगिंग फेस द्वारा लॉन्च किए गए "हगिंग चैट" नामक iOS ऐप को भी आज़मा सकते हैं।
ऐप को मैजिक हेमी डिस्ट्रिक्ट ऐप स्टोर खाते की मदद से डाउनलोड किया जा सकता है, और फिर उपयोगकर्ता विभिन्न ओपन सोर्स मॉडल तक पहुंच और उपयोग कर सकते हैं, जिसमें फी 3 भी शामिल है, लेकिन यह इन्हीं तक सीमित नहीं है।
मिक्सट्रल, कमांड आर+ और अन्य मॉडल।
हार्दिक अनुस्मारक, बेहतर अनुभव और प्रदर्शन के लिए, iPhone के नवीनतम पीढ़ी के प्रो संस्करण का उपयोग करने की अनुशंसा की जाती है।
डाउनलोड लिंक: https://apps.apple.com/us/app/huggingchat/id6476778843
# Aifaner के आधिकारिक WeChat सार्वजनिक खाते का अनुसरण करने के लिए आपका स्वागत है: Aifaner (WeChat ID: ifanr) आपको जल्द से जल्द अधिक रोमांचक सामग्री प्रदान की जाएगी।