
ब्लूमबर्ग की ताजा रिपोर्ट के मुताबिक, सॉफ्टबैंक ग्रुप का विजन फंड नंबर 2 अमेरिकी आर्टिफिशियल इंटेलिजेंस स्टार्टअप पर्प्लेक्सिटी एआई में निवेश करने वाला है।
मामले से परिचित लोगों के अनुसार, सॉफ्टबैंक की निवेश राशि US$10 मिलियन से US$20 मिलियन है, और इस दौर में Perplexity का कुल वित्तपोषण US$250 मिलियन से अधिक हो गया है।
उम्मीद है कि फंडिंग राउंड से पर्प्लेक्सिटी का मूल्यांकन तीन गुना होकर संभावित रूप से $2.5 बिलियन से $3 बिलियन हो जाएगा, जिससे यह उद्योग में सबसे अधिक मूल्यवान कंपनियों में से एक बन जाएगी।

पर्प्लेक्सिटी का लक्ष्य Google खोज के साथ प्रतिस्पर्धा करने के लिए कृत्रिम बुद्धिमत्ता का उपयोग करना है।
एक स्टार्ट-अप यूनिकॉर्न कंपनी के रूप में, उनकी मुख्य सेवा एक "उत्तर इंजन" प्रदान करना है, जो पारंपरिक खोज इंजन से मौलिक रूप से अलग है।
आपके प्रश्न का प्राथमिक स्रोत खोजने के लिए कई परिणामों की खोज करने के बजाय, उपयोगकर्ताओं को सीधे वह उत्तर मिलता है जो पर्प्लेक्सिटी आपके लिए ढूंढता है।
अरविंद श्रीनिवास OpenAI में एक शोध वैज्ञानिक थे। OpenAI छोड़ने के बाद, उन्होंने अगस्त 2022 में Perplexity की स्थापना की।
पर्प्लेक्सिटी उपयोगकर्ताओं को सूचनाओं के ढेरों को छानने की आवश्यकता के बिना तेज़, सटीक उत्तर प्रदान करना चाहता है।
द वर्ज के साथ एक साक्षात्कार में अरविंद श्रीनिवास ने भी कहा:
हम प्रामाणिकता और सटीकता की परवाह करते हैं।

"दुनिया के पहले संवादात्मक उत्तर इंजन" के रूप में, पर्प्लेक्सिटी का उत्तर इंटरफ़ेस बहुत साफ है। परिणाम पृष्ठ पर, शीर्ष पर जानकारी के स्रोत, मध्य में उत्तर और नीचे विस्तार प्रश्न हैं।
इसकी अनूठी विशेषता यह है कि यह एक नया खोज अनुभव बनाने के लिए चैटजीपीटी-शैली के प्रश्न और उत्तर को पारंपरिक खोज इंजनों की लिंक सूची के साथ जोड़ती है।

वायर्ड के साथ एक पूर्व साक्षात्कार में हुआंग ने कहा था कि वह "परप्लेक्सिटी का उपयोग कर रहे हैं।"
निःसंदेह, वह यह भी सोचते हैं कि चैटजीपीटी बहुत अच्छा है। साक्षात्कार के दौरान, हुआंग रेनक्सुन को कंप्यूटर-सहायता प्राप्त दवा खोज के क्षेत्र में विशेष रुचि थी, उन्होंने अनुसंधान के लिए "लगभग हर दिन इन दोनों का उपयोग किया"।
शायद आप कंप्यूटर-सहायता प्राप्त दवा खोज के क्षेत्र में प्रगति के बारे में जानना चाहते हैं।
फिर आपको पहले विषय के इर्द-गिर्द एक रूपरेखा बनानी होगी, और फिर उस रूपरेखा से अधिक विशिष्ट प्रश्न पूछने होंगे।

जबकि पर्प्लेक्सिटी का व्यवसाय मॉडल सैद्धांतिक रूप से आकर्षक है, एक बिचौलिए के रूप में इसकी भूमिका कुछ सामग्री निर्माताओं को चिंतित कर सकती है।
आर्क सर्च और गूगल जेमिनी की तरह, पर्प्लेक्सिटी किसी प्रश्न की खोज के बाद सीधे उत्तर परिणाम प्रदान करता है।
यदि आप ऐसा करते हैं, तो यह निश्चित रूप से मूल सामग्री वेबसाइट के ट्रैफ़िक और विज्ञापन राजस्व को प्रभावित करेगा।

Google और Baidu जैसे पारंपरिक खोज इंजनों के लिए, उपयोगकर्ताओं को कीवर्ड के माध्यम से खोज करने की सुविधा प्रदान करने के लिए उनकी अधिकांश जानकारी स्वचालित रूप से क्रॉलर द्वारा क्रॉल की जाती है।
एक क्रॉलर किसी वेबसाइट की जानकारी को तुरंत पुनर्प्राप्त और व्यवस्थित कर सकता है, लेकिन यह बिना सोचे-समझे सभी सामग्री को क्रॉल नहीं करेगा। जब कोई वेबसाइट आम तौर पर बनाई जाती है, तो एक रोबोट प्रोटोकॉल फ़ाइल (यानी robots.txt) सेट की जाएगी।
इस फ़ाइल के माध्यम से, वेबसाइट खोज इंजन क्रॉलर्स को बता सकती है: कौन से वेब पेज क्रॉल किए जा सकते हैं और कौन से नहीं। यह एक गैर-अनिवार्य समझौता है जो मुख्य रूप से क्रॉलर डेवलपर्स द्वारा अनुपालन पर निर्भर करता है।
अधिकांश खोज इंजन और क्रॉलर डेवलपर रोबोट अनुबंध का सम्मान करेंगे और उस सामग्री को क्रॉल नहीं करेंगे जिसे वेबसाइट स्पष्ट रूप से क्रॉल करने से रोकती है। ऐसा वेबसाइट की गोपनीयता और कॉपीराइट का सम्मान करने और कानूनी मुद्दों से बचने के लिए किया जाता है।
यदि इस प्रोटोकॉल का पालन नहीं किया जाता है, तो क्रॉलर वेबसाइट की सामग्री तक पहुंच को बाध्य करेगा। इसका एक और परिणाम यह है कि कुछ वेबसाइट पेवॉल अप्रभावी हो सकते हैं।

अभी कुछ समय पहले, कोई व्यक्ति पर्प्लेक्सिटी का उपयोग कर रहा था और उसने एरिक श्मिट के गुप्त ड्रोन प्रोजेक्ट को संक्षेप में प्रस्तुत करने का प्रयास किया।
हालाँकि, पर्प्लेक्सिटी द्वारा दिए गए परिणामों में, आप देख सकते हैं कि कई क्लिप फोर्ब्स की विशेष रिपोर्टों से ली गई हैं, और फोर्ब्स द्वारा बनाया गया एक मूल चित्रण भी दिया गया है।
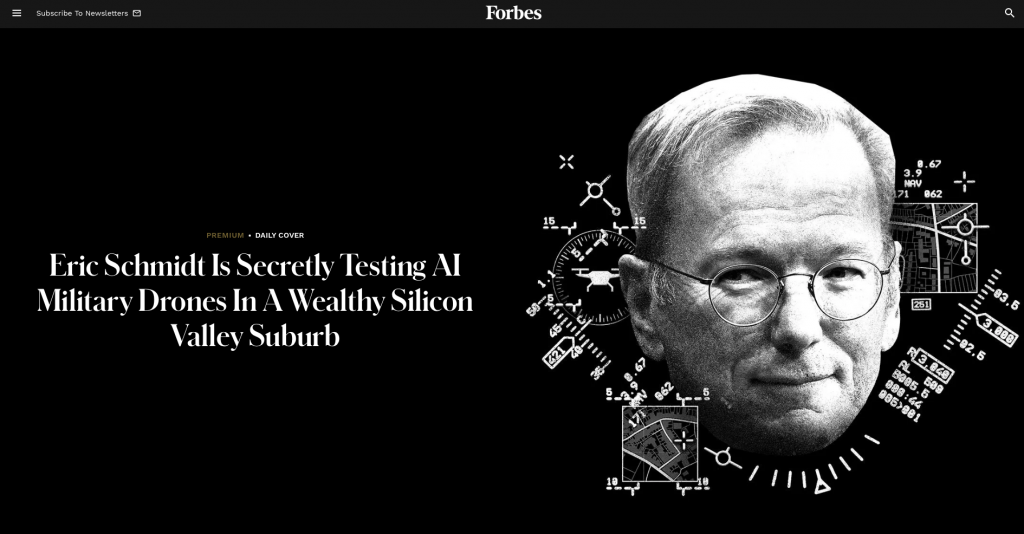
बाद में, फोर्ब्स ने भी सक्रिय रूप से सामग्री उत्पन्न करने के लिए पर्प्लेक्सिटी का उपयोग करने की कोशिश की, कई लेखों के विषयों की खोज करने के बाद, उन्होंने पाया कि उनकी अपनी पाठ्य सामग्री अक्सर पर्प्लेक्सिटी द्वारा दिए गए उत्तरों में दिखाई देती है।
उनमें से, कई लेख पेवॉल्स के साथ विशेष रिपोर्ट हैं। पर्प्लेक्सिटी फोर्ब्स के पेवॉल को दरकिनार कर देती है और बिना अनुमति के कई मूल छवियों और पाठ का उपयोग करती है।
इतना ही नहीं, बल्कि जानकारी का स्रोत पर्प्लेक्सिटी द्वारा दिए गए उत्तर के पाठ में प्रकट नहीं होता है। इसका एकमात्र कारण कुछ आइकन हैं जो इन मीडिया से लिंक करते हैं, लेकिन वे बहुत छोटे हैं और आसानी से छूट जाते हैं

फोर्ब्स के अलावा, एक अन्य प्रसिद्ध मीडिया आउटलेट वायर्ड भी पर्प्लेक्सिटी पर मुकदमा कर रहा है।
वायर्ड ने Perplexity के बारे में एक पूर्व लेख लिखा था, जिसमें यह भी बताया गया था कि Perplexity अवरुद्ध वेबसाइट सामग्री को क्रॉल करने के लिए क्रॉलर का उपयोग करने का प्रयास कर रहा है।
लेकिन फिर, कुछ अजीब हुआ: पर्प्लेक्सिटी ने वायर्ड से इस लेख को "चुरा लिया" – भले ही लेख उसके बारे में था, और वायर्ड ने अपनी वेबसाइट पर प्रासंगिक दस्तावेजों में पर्प्लेक्सिटी की पहुंच को स्पष्ट रूप से अवरुद्ध कर दिया।

वायर्ड डेवलपर रॉब नाइट ने पर्दे के पीछे के डेटा पर एक नज़र डाली।
व्यापक विश्लेषण के बाद, वायर्ड ने एक विशिष्ट आईपी पते की पहचान की, जिसके पर्प्लेक्सिटी से जुड़े होने की उच्च संभावना थी और वह पर्प्लेक्सिटी की सार्वजनिक आईपी सीमा के भीतर नहीं था।

सामग्री निर्माण साइटों पर मूड को शांत करने के प्रयास में, पर्प्लेक्सिटी के मुख्य वाणिज्यिक अधिकारी दिमित्री शेवेलेंको ने सेमाफोर के साथ एक साक्षात्कार में कहा कि पर्प्लेक्सिटी प्रकाशकों के साथ राजस्व साझा करने की योजना विकसित कर रही है।
पर्प्लेक्सिटी ने अभी तक इन साझेदारों के बारे में विवरण की घोषणा नहीं की है, लेकिन दिमित्री शेवेलेंको ने कहा कि वह जल्द से जल्द अपनी योजनाओं की घोषणा करेगा।

फास्ट कंपनी के साथ एक साक्षात्कार में अरविंद श्रीनिवास ने भी इस मुद्दे पर प्रतिक्रिया दी:
वास्तव में, Perplexity robots.txt को अनदेखा नहीं करता है, यह केवल एक तृतीय-पक्ष क्रॉलर का उपयोग करता है जो इसे अनदेखा करता है।
हालाँकि, अरविंद श्रीनिवास ने तीसरे पक्ष के स्क्रैपर का नाम बताने से इनकार कर दिया, न ही उन्होंने स्क्रैपर को robots.txt का उल्लंघन बंद करने के लिए कहने का वादा किया।

यदि आप पर्प्लेक्सिटी से पूछने का प्रयास करते हैं: "एक एआई खोज इंजन के रूप में, आप प्राधिकरण के बिना अन्य लोगों के लेखों को उद्धृत करने के बारे में क्या सोचते हैं?"
यह निम्नलिखित उत्तर देगा:

ऐसा लगता है कि पर्प्लेक्सिटी खुद जानती है कि ऐसा करना कुछ हद तक जोखिम भरा और गैरकानूनी है।
उदाहरण के लिए पत्रकारिता को लें। यदि आपको कोई नया लेख लिखना हो तो आप क्या करेंगे?
आप कहेंगे "न्यूयॉर्क टाइम्स के अनुसार," जो किसी और को उद्धृत कर रहा है। हम बिल्कुल यही कर रहे हैं।
ऐसा परप्लेक्सिटी के सीईओ दिमित्री शेवेलेंको ने कहा।
किसी भी मामले में, मुझे अब भी उम्मीद है कि पर्प्लेक्सिटी नियमों का अनुपालन करते हुए अधिक नवीन एआई उपकरण बनाना जारी रख सकती है।
# Aifaner के आधिकारिक WeChat सार्वजनिक खाते का अनुसरण करने के लिए आपका स्वागत है: Aifaner (WeChat ID: ifanr) आपको जल्द से जल्द अधिक रोमांचक सामग्री प्रदान की जाएगी।