

कृत्रिम बुद्धिमत्ता की सफलता केवल पिरामिड के शीर्ष पर मौजूद प्रतिभाओं के कारण ही नहीं है।
एआई वस्तुओं को नहीं पहचानता है और चेहरे की विशेषताओं और ट्रैफिक लाइट में अंतर करना सीखने के लिए बहुत अधिक डेटा की आवश्यकता होती है।
एआई जानकारी से इनकार नहीं करता है, डेटाबेस के हानिकारक हिस्सों को खत्म करने में मदद करने के लिए मनुष्यों पर भरोसा करता है।
जब एआई अंततः सुर्खियों में आ जाता है, तो डेटा एनोटेटर अपने नीरस लेकिन महत्वपूर्ण कर्तव्यों का पालन करते हैं, और फिर अंधेरे में खो जाते हैं।
ChatGPT, जो पूरी दुनिया में लोकप्रिय है, शायद "एक सफल होगा और सभी मरेंगे" की कहानी भी है।
चैटजीपीटी का "पर्दे के पीछे के नायक"
यह कहे बिना जाता है कि चैटजीपीटी कितना शक्तिशाली है। यह आपसे प्राकृतिक भाषा में बात करता है, कोड लिखता है, पेपर लिखता है, परीक्षा पास करता है और कविता बनाता है।
पिछले "कृत्रिम मानसिक मंदता" की तुलना में, GPT-3, ChatGPT के पूर्ववर्ती, भी एक बड़ा सुधार है, लेकिन इसमें एक समस्या है कि हिंसा, लिंगवाद और नस्लवादी टिप्पणियों को उगलना आसान है, इसलिए इसे वास्तव में लोकप्रिय नहीं बनाया जा सकता है .
अतीत से सीखे गए पाठों के साथ, यह सुनिश्चित करने के लिए कि चैटजीपीटी कोमल और हानिरहित है, ओपनएआई ने एक अतिरिक्त सुरक्षा तंत्र स्थापित किया है।

▲ चित्र: शटरस्टॉक
हिंसा, घृणा और यौन दुर्व्यवहार से जुड़े उदाहरणों के आधार पर, यह एक एआई को प्रशिक्षित करता है जो हानिकारक सामग्री का पता लगा सकता है, और फिर इस एआई को उपयोगकर्ताओं तक पहुंचने से पहले सामग्री का पता लगाने और फ़िल्टर करने के लिए चैटजीपीटी में निर्मित एक डिटेक्टर के रूप में उपयोग करता है।
उपरोक्त उदाहरणों को डेटा लेबलिंग (डेटा लेबलिंग) से गुज़रना पड़ता है, जो एक बहुत बड़ा मानव श्रम है, और केन्या में श्रमिक हानिकारक सामग्री को लेबल करने के लिए ज़िम्मेदार हैं।
नवंबर 2021 से, OpenAI ने आउटसोर्सिंग कंपनी समा को दसियों हज़ार टेक्स्ट फ़्रैगमेंट भेजे हैं, जिनमें से अधिकांश इंटरनेट के सबसे गहरे कोनों को दर्शाते हैं, जिसमें यौन शोषण, आत्महत्या, यातना आदि शामिल हैं।

▲ चित्र: समा
एक डेटा लेबलर ने अस्वीकार्य रूप से हानिकारक सामग्री को पढ़ने के बाद बार-बार मतिभ्रम का अनुभव करना शुरू कर दिया।
बेहतर इलाज के लिए काम के बोझ का आदान-प्रदान नहीं किया गया है।
द टाइम की जांच में पाया गया कि समा डेटा लेबलर जो ओपनएआई के लिए काम करते हैं, वे लगभग $1.32 से $2 प्रति घंटा कमाते हैं। नौ घंटे की शिफ्ट में काम करते हुए, उन्होंने पाठ के 150 से 250 अनुच्छेदों को पढ़ा और व्याख्या की, प्रत्येक 100 शब्दों से लेकर 1,000 से अधिक शब्दों तक।
लेकिन समा का कहना है कि कर्मचारी अधिकतम 250 के बजाय प्रति नौ घंटे की शिफ्ट में 70 पैराग्राफ की व्याख्या कर सकते हैं, और करों के एक घंटे बाद $1.46 और $3.74 के बीच कमा सकते हैं।

समा खुद को एक "नैतिक एआई कंपनी" के रूप में भी वर्णित करता है जिसने 50,000 से अधिक लोगों को गरीबी से बाहर निकाला है।
अगर नैतिक होने का मतलब गरीबी से बाहर निकलने में मदद करना है, तो इसमें कुछ भी गलत नहीं है, आखिरकार इन गरीब श्रमिकों के पास और विकल्प नहीं हैं।
लेकिन "दुष्प्रभाव" एक छाया की तरह हैं, और शारीरिक और मानसिक यातना एक आवश्यक कीमत बन गई है।
क्योंकि समा की कर्मचारियों की कार्यकुशलता के लिए अत्यधिक उच्च आवश्यकताएं हैं, कंपनी शायद ही कभी मनोवैज्ञानिक परामर्श गतिविधियों का आयोजन करती है, यह उल्लेख करने की आवश्यकता नहीं है कि ये गतिविधियाँ स्वयं किसी काम की नहीं हैं। कुछ कर्मचारियों ने आमने-सामने परामर्श करने की पेशकश की है, लेकिन समा प्रबंधन ने बार-बार मना कर दिया है।

OpenAI ने विदेशी मीडिया क्वार्ट्ज को भी जवाब दिया कि वे पूर्वी अफ्रीका में अन्य सामग्री समीक्षा कंपनियों की तुलना में लगभग दोगुना भुगतान करते हैं और कर्मचारियों को लाभ और पेंशन प्रदान करते हैं।
हालाँकि पार्टियों की अलग-अलग राय है, लेकिन मूल तथ्य अलग नहीं हैं।
AI को सुरक्षित बनाने और OpenAI के सामान्य AI को मानव जाति के लिए लाभकारी बनाने के लिए, बड़ी संख्या में श्रमिकों ने बहुत अधिक ऊर्जा का भुगतान किया है और यहां तक कि आघात भी झेला है। लेकिन जब OpenAI का मूल्य लगभग $30 बिलियन था, तो वे काफी हद तक अनजान बने रहे।
टर्मिनल केशिकाएं
डेटा लेबलर कोई नया काम नहीं है।
2007 की शुरुआत में, कंप्यूटर दृष्टि विशेषज्ञ फी-फी ली ने $10/घंटे के लिए डेटा लेबलिंग के साथ प्रयोग करने के लिए प्रिंसटन स्नातक के एक समूह को काम पर रखा था।
आज, डेटा लेबलिंग पहले से ही एक उद्योग के रूप में विकसित हो चुका है, लेकिन वेतन में काफी गिरावट आई है, और नायक अब कॉलेज के छात्र नहीं हैं।
2019 के आसपास, कुछ मीडिया ने घरेलू डेटा लेबलर्स पर सूचना दी जो हेनान, शेडोंग, हेबेई और अन्य स्थानों में चौथे-स्तरीय और पांचवें-स्तरीय शहरों में बिखरे हुए थे।

इसी तरह, समा का मुख्यालय सैन फ्रांसिस्को में है और केन्या, युगांडा और भारत में कर्मचारी कार्यरत हैं। OpenAI के अलावा, यह Google, मेटा और Microsoft जैसे सिलिकॉन वैली क्लाइंट्स के डेटा को भी लेबल करता है।
हालाँकि, पिछले दो वर्षों में, समा ने "सुनहरे बेसिन में अपने हाथ धोने" का मन बना लिया है।
फरवरी 2022 में, समा ने OpenAI के साथ अपने सहयोग को समाप्त करने का फैसला किया। कर्मचारियों को अब दर्द नहीं सहना पड़ता है, लेकिन आजीविका को बनाए रखना भी मुश्किल होता है। "हमारे लिए, यह हमारे परिवार का समर्थन करने का एक तरीका है।"

इस साल जनवरी में, समा का रवैया और भी निर्णायक था। उन्होंने सभी प्राकृतिक भाषा प्रसंस्करण और सामग्री समीक्षा कार्य को छोड़ने की योजना बनाई, केवल कंप्यूटर विज़न डेटा एनोटेशन करते हैं, और मेटा के साथ अनुबंध को समाप्त करने सहित संवेदनशील सामग्री से जुड़े सभी व्यवसायों के साथ अलग-अलग तरीके अपनाते हैं। पूर्वी अफ़्रीका।
समा के कर्मचारी, जो अफ्रीका में अपने नैरोबी कार्यालय में मेटा के लिए काम करते हैं, स्थानीय रूप से निर्मित सामग्री, सिर कलम करने, बाल शोषण आदि की समीक्षा करने पर ध्यान केंद्रित करते हैं, वे जितना संभाल सकते हैं, उससे कहीं अधिक है। एक कर्मचारी ने छवियों की सामग्री की समीक्षा को "एक डरावनी फिल्म में रहने" के रूप में वर्णित किया।
जहां मांग होती है, वहां बाजार होता है और ऐसी आउटसोर्सिंग कंपनियों की कभी कमी नहीं होती।
अफ्रीका में टिकटॉक की मॉडरेशन सेवाओं के लिए जिम्मेदार लक्समबर्ग स्थित आउटसोर्सिंग कंपनी मजोरेल कथित तौर पर मेटा का काम संभालने के लिए तैयार है।

कंपनी की आलोचना भी की गई है। अगस्त 2022 में, इनसाइडर ने मोरक्को के मजोरेल में स्थिति की जांच की, और पाया कि श्रमिक अक्सर 12 घंटे से अधिक समय तक शिफ्ट में काम करते हैं, पशु क्रूरता, यौन हिंसा आदि से जुड़े छोटे वीडियो चिह्नित करते हैं, और उनके अमेरिकी समकक्षों की तुलना में कम आराम का समय होता है। कंपनी के "स्वास्थ्य सलाहकार" ने कुछ नहीं करने में मदद की।
प्रौद्योगिकी उद्योग श्रृंखला के अंत में केशिकाओं के रूप में, डेटा एनोटेशन अधिक स्थानों पर दिखाई देता है।
नवंबर 2022 में, द वर्ज ने बताया कि अमेज़ॅन ने भारत और कोस्टा रिका में श्रमिकों को काम पर रखा है जो अमेज़ॅन के कंप्यूटर विज़न सिस्टम को बेहतर बनाने के लिए वेयरहाउस कैमरों से हजारों वीडियो देखने के लिए जिम्मेदार हैं।

▲ चित्र: रॉयटर्स
लेकिन कम से कम आठ घंटे तक इसे घूरने से उन्हें सिरदर्द, आंखों में दर्द और दृष्टि हानि हो गई।
स्व-ड्राइविंग कारों को भी डेटा लेबलिंग की आवश्यकता होती है ताकि यह सीख सकें कि सड़क के संकेतों, वाहनों, पैदल चलने वालों, पेड़ों और कचरे के डिब्बे को कैसे पहचाना जाए। इसके लिए उच्च लेबलिंग सटीकता की आवश्यकता होती है, क्योंकि यह लोगों के जीवन और मृत्यु को सीधे निर्धारित कर सकती है।

अप्रैल 2022 में एमआईटी टेक्नोलॉजी रिव्यू की जांच में पाया गया कि टेस्ला सहित सेल्फ-ड्राइविंग कंपनियों में वेनेजुएला के कर्मचारियों ने सेल्फ-ड्राइविंग डेटा को केवल 90 सेंट प्रति घंटे के औसत वेतन के लिए एनोटेट किया था।
कम से कम अभी के लिए, डेटाबेस को अभी भी मानव शुद्धिकरण की आवश्यकता है, और एआई मानचित्र पहचान को अभी भी फ्रेम खींचने के लिए मनुष्यों की आवश्यकता है। समस्या यह है कि वे जो ऊर्जा लगाते हैं, उसकी तुलना में श्रमिकों का उपचार और मानसिक स्वास्थ्य इतना आदर्श नहीं है।
जो अधिक से अधिक सीमांत होते जा रहे हैं
ChatGPT के जन्म के बाद से, बहुत से लोग अपनी नौकरी के बारे में चिंतित हैं। यह संकट की एक बहुत विशिष्ट भावना हो सकती है।
उसी समय, एआई और मनुष्यों के बीच के संबंध में एक और आयाम में सूक्ष्म परिवर्तन हुए हैं – इसने मनुष्यों के काम करने के तरीके और मौजूदा प्रकार की नौकरियों को बदल दिया है, जिससे बड़ी संख्या में मजदूरों को पर्दे के पीछे छिपने की अनुमति मिलती है।
उदाहरण के लिए, डेटा लेबलर, जिनकी नौकरी की सीमा अधिक नहीं है, अक्सर कठिन शैक्षणिक आवश्यकताएं नहीं होती हैं, और कुछ दिनों के प्रशिक्षण के बाद उन्हें नियोजित किया जा सकता है। यदि आप जानते हैं कि क्या चिन्हित करना है और कहाँ चिन्हित करना है , तो आप मूल रूप से आरंभ कर रहे हैं, और अभ्यास करने के लिए शेष समय को परिपूर्ण बनाता है।

वे अक्सर नियमित कर्मचारी नहीं होते हैं, लेकिन आउटसोर्स फॉर्म होते हैं, जैसे ओपनएआई की सेवा करने वाले केन्याई कर्मचारी।
इसका मतलब यह है कि वे एक अधिक अस्थिर दुनिया में रहते हैं, कम वेतन के साथ, अधिक सीमांत स्थिति, और कार्यस्थल में कम आवाज, बस सूट का पालन करते हुए। एआई कितनी दूर जा रहा है, वे नहीं जानते होंगे।
2018 में, जीक्यू रिपोर्ट में "द हू हू वर्क फॉर आर्टिफिशियल इंटेलिजेंस" का उल्लेख किया गया था: "हमारे पास कोई अनुसंधान और विकास क्षमता नहीं है, और हम विशुद्ध रूप से (फाउंड्री) फॉक्सकॉन हैं।"
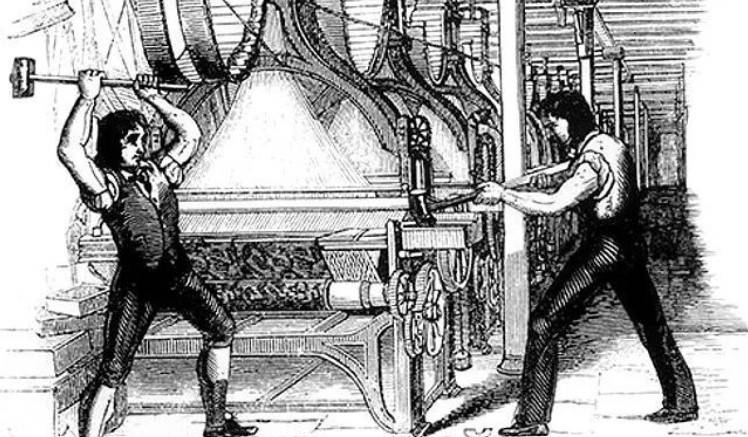
▲ लुडाइट आंदोलन।
इसी तरह के हालात इतिहास में सामने आए हैं। 19वीं शताब्दी की शुरुआत में ब्रिटेन में, स्वचालित कपड़ा मशीनें लोकप्रिय हो गईं, और कारखानों ने मशीनों को संचालित करने के लिए सस्ते अकुशल श्रम को किराए पर लेना पसंद किया, जिसके परिणामस्वरूप कई कुशल मैनुअल श्रमिकों की बेरोजगारी हुई।
समय का पहिया लगातार आगे बढ़ रहा है, और एआई की सेवा करने वाले डेटा लेबलर्स को धीरे-धीरे एआई द्वारा प्रतिस्थापित किया जा रहा है।
जून 2022 में, टेस्ला ने 200 अमेरिकी कर्मचारियों की छंटनी करने की योजना बनाई है जो वीडियो की व्याख्या करने और ड्राइवर सहायता प्रणालियों को बेहतर बनाने में मदद करने के लिए जिम्मेदार हैं। इसका कारण यह हो सकता है कि हाल के वर्षों में टेस्ला की स्वचालित डेटा लेबलिंग में प्रगति हुई है, जो मनुष्यों द्वारा किए गए कुछ कार्यों को प्रतिस्थापित कर सकती है।

टेस्ला ऑटोपायलट के सॉफ्टवेयर निदेशक ने एआई दिवस पर एक बार कहा था कि कंपनी एक सप्ताह में 45 से 60 सेकंड के 10,000 वीडियो क्लिप एकत्र और स्वचालित रूप से लेबल कर सकती है। इसके विपरीत, "प्रत्येक खंड को मैन्युअल रूप से लेबल करने में महीनों लग सकते हैं।"
2020 में, वर्ल्ड इकोनॉमिक फोरम ने भविष्यवाणी की थी कि 2025 तक, 85 मिलियन नौकरियों को मशीनों द्वारा प्रतिस्थापित किया जाएगा, और 97 मिलियन नए रोजगार सृजित होंगे।

वे जिन पदों के बारे में आशावादी हैं, वे मूल रूप से तकनीकी प्रतिभाएं हैं जैसे कि कृत्रिम बुद्धिमत्ता और मशीन सीखने के विशेषज्ञ, डिजिटल परिवर्तन विशेषज्ञ और सूचना सुरक्षा विश्लेषक।
इसके विपरीत, निम्न-आय और कम-कुशल व्यवसाय धीरे-धीरे मंच से पीछे हट रहे हैं, और अंततः मशीनों की छाया में गायब हो सकते हैं।
#Aifaner के आधिकारिक WeChat सार्वजनिक खाते पर ध्यान देने के लिए आपका स्वागत है: Aifaner (WeChat ID: ifanr), जितनी जल्दी हो सके आपके लिए अधिक रोमांचक सामग्री प्रस्तुत की जाएगी।