

OpenAI o1 को रिलीज़ हुए एक सप्ताह हो गया है, लेकिन यह अभी भी एक प्याज जैसा रहस्य है, जो परत दर परत सुलझने का इंतज़ार कर रहा है।
गीक्स कैसे खेल सकते हैं इसकी कोई सीमा नहीं है, उन्हें आईक्यू टेस्ट देने दें, कॉलेज प्रवेश परीक्षा के पेपर लिखने दें और सिफर टेक्स्ट को समझने दें। ऐसे उपयोगकर्ता भी हैं जो काम करने के लिए AI का उपयोग करते हैं और उन्हें लगता है कि o1 का उपयोग करना इतना आसान नहीं है, लेकिन वे नहीं जानते कि यह उनकी अपनी समस्या है या AI की समस्या है।
हम सभी जानते हैं कि यह तर्क करने में अच्छा है, लेकिन क्यों? हमारे पुराने मित्र GPT-4o की तुलना में, o1 का क्या फायदा है और यह कहाँ उपयोग के लिए उपयुक्त है?
हमने कुछ प्रश्न एकत्र किए हैं जिनके बारे में आप चिंतित हो सकते हैं और उन्हें सामान्य लोगों के करीब लाने के लिए यथासंभव स्पष्ट रूप से उत्तर दिए हैं।
o1 क्या खास है?
ओ1 ओपनएआई का हाल ही में जारी अनुमान मॉडल है। वर्तमान में इसके दो संस्करण हैं: ओ1-पूर्वावलोकन और ओ1-मिनी।
इसके बारे में सबसे विशिष्ट बात यह है कि यह उत्तर देने से पहले सोचता है, एक लंबी आंतरिक सोच श्रृंखला उत्पन्न करता है, चरण दर चरण तर्क करता है, और जटिल समस्याओं के बारे में सोचने की मानवीय प्रक्रिया का अनुकरण करता है।

▲OpenAI
ऐसा करने की क्षमता ओ1 के सुदृढीकरण सीखने के प्रशिक्षण से आती है।
यदि पिछले बड़े मॉडल डेटा सीख रहे थे, तो ओ1 सीखने की सोच की तरह है।
ठीक उसी प्रकार जब हम किसी समस्या का समाधान करते हैं, तो हमें न केवल उत्तर लिखना चाहिए, बल्कि तर्क प्रक्रिया भी लिखनी चाहिए। आप किसी प्रश्न को रटकर याद कर सकते हैं, लेकिन यदि आप तर्क करना सीख जाते हैं, तो आप निष्कर्ष निकाल सकते हैं।

यदि हम अल्फ़ागो की उपमा लें, जिसने गो के विश्व चैंपियन को हराया, तो इसे समझना आसान है।
अल्फ़ागो को सुदृढीकरण सीखने के माध्यम से प्रशिक्षित किया जाता है। यह पहले पर्यवेक्षित सीखने के लिए बड़ी संख्या में मानव शतरंज रिकॉर्ड का उपयोग करता है, और फिर प्रत्येक खेल में जीत या हार के आधार पर इसे पुरस्कृत या दंडित किया जाता है, और लगातार अपने शतरंज कौशल में सुधार करता है। और यहां तक कि उन तरीकों में महारत हासिल करना जिनके बारे में मानव शतरंज खिलाड़ी सोच भी नहीं सकते।
o1 और AlphaGo समान हैं, लेकिन AlphaGo केवल Go चला सकता है, जबकि o1 एक सामान्य प्रयोजन वाला बड़ा भाषा मॉडल है।
ओ1 द्वारा सीखी गई सामग्रियां उच्च-गुणवत्ता वाले कोड, गणित प्रश्न बैंक आदि हो सकती हैं। फिर ओ1 को समस्याओं को हल करने के लिए एक सोच श्रृंखला उत्पन्न करने के लिए प्रशिक्षित किया जाता है, और पुरस्कार या दंड तंत्र के तहत, वह लगातार सुधार करने के लिए अपनी सोच श्रृंखला उत्पन्न और अनुकूलित करता है। तर्क क्षमता.

यह वास्तव में बताता है कि ओपनएआई ओ1 की मजबूत गणित और कोडिंग क्षमताओं पर जोर क्यों देता है, क्योंकि सही और गलत को सत्यापित करना आसान है, और सुदृढीकरण सीखने का तंत्र स्पष्ट प्रतिक्रिया प्रदान कर सकता है, जिससे मॉडल के प्रदर्शन में सुधार हो सकता है।
o1 किस प्रकार की नौकरियाँ आपके लिए उपयुक्त हैं?
OpenAI के मूल्यांकन परिणामों से देखते हुए, o1 एक सुयोग्य विज्ञान समस्या समाधानकर्ता है, जो विज्ञान, कोडिंग, गणित और अन्य क्षेत्रों में जटिल समस्याओं को हल करने के लिए उपयुक्त है, और इसने कई परीक्षाओं में उच्च अंक प्राप्त किए हैं।
इसने कोडफोर्सेस प्रोग्रामिंग प्रतियोगिताओं में 89% प्रतिभागियों को पीछे छोड़ दिया, अमेरिकी गणितीय ओलंपियाड के लिए अर्हता प्राप्त करने में देश में शीर्ष 500 में स्थान प्राप्त किया, और भौतिकी, जीव विज्ञान और रसायन विज्ञान समस्याओं पर बेंचमार्क पर मानव पीएचडी-स्तर की सटीकता को पार कर लिया।
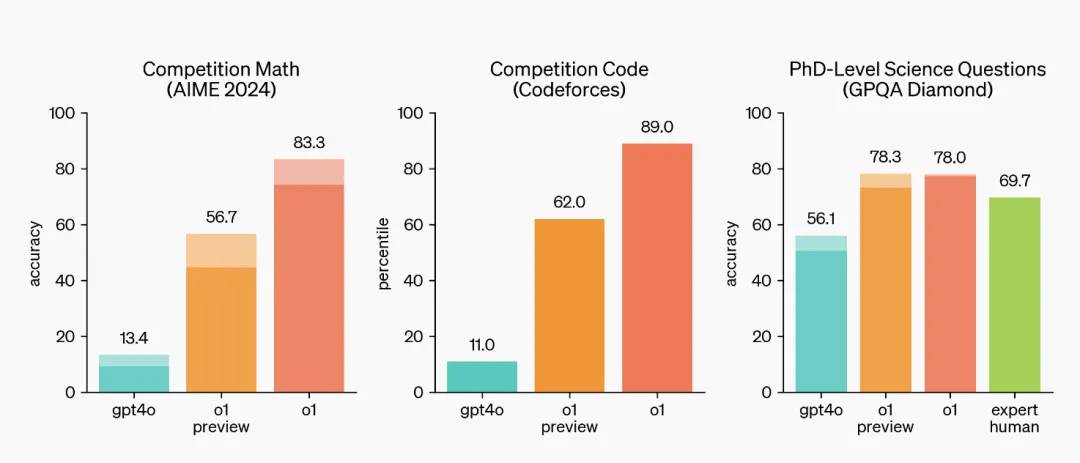
O1 की उत्कृष्टता वास्तव में एक समस्या को दर्शाती है: जैसे-जैसे AI अधिक स्मार्ट होता जा रहा है, उनकी क्षमताओं को कैसे मापा जाए यह एक समस्या बन जाती है। O1 के लिए, अधिकांश मुख्यधारा बेंचमार्क अर्थहीन हैं।
वर्तमान घटनाओं को ध्यान में रखते हुए, ओ1 जारी होने के एक दिन बाद, डेटा एनोटेशन कंपनी स्केल एआई और गैर-लाभकारी संगठन सीएआईएस ने दुनिया भर से एआई परीक्षा प्रश्न एकत्र करना शुरू कर दिया, क्योंकि वे चिंतित थे कि एआई खराब तरीके से सीखेगा प्रश्न हथियारों से संबंधित नहीं हो सकते।
सबमिशन मांगने की अंतिम तिथि 1 नवंबर है। अंततः, वे इतिहास में सबसे कठिन बड़े-मॉडल ओपन सोर्स बेंचमार्क बनाने की उम्मीद करते हैं, एक आकर्षक नाम के साथ: ह्यूमैनिटीज लास्ट एग्जाम।

वास्तविक माप के अनुसार, o1 का स्तर संतोषजनक नहीं है – कोई गलत मुहावरों का उपयोग नहीं किया गया है, और यह आम तौर पर संतोषजनक है।
गणितज्ञ टेरेंस ताओ का मानना है कि o1 का उपयोग करना एक स्नातक छात्र को निर्देश देने जैसा है जो औसत है लेकिन बहुत बेकार नहीं है।
जटिल विश्लेषण समस्याओं से निपटने के दौरान, ओ1 अपने तरीके से अच्छे समाधान पेश कर सकता है, लेकिन उसके पास अपनी प्रमुख अवधारणाएं और विचार नहीं होते हैं, और वह कुछ बड़ी गलतियाँ भी करता है।
इस प्रतिभाशाली गणितज्ञ को कठोर होने के लिए दोष न दें, उनकी राय में, GPT-4 जैसे पुराने मॉडल बेकार स्नातक छात्र हैं।

अर्थशास्त्री टायलर कोवेन ने अर्थशास्त्र डॉक्टरेट स्तर की परीक्षा के लिए एक प्रश्न भी दिया। इसके बारे में सोचने के बाद, एआई ने इसे सरल शब्दों में संक्षेपित किया, "आप कोई भी अर्थशास्त्र प्रश्न पूछ सकते हैं, और उत्तर अच्छा है।"
संक्षेप में, आप सभी पीएचडी-स्तर की समस्याओं को भी ले सकते हैं और O1 परीक्षा दे सकते हैं।
o1 आप अभी किसमें अच्छे नहीं हैं?
शायद कई लोगों के लिए, o1 बेहतर उपयोगकर्ता अनुभव नहीं लाता है, इसके विपरीत, o1 टिक-टैक-टो जैसे कुछ सरल प्रश्नों को पलट देगा।
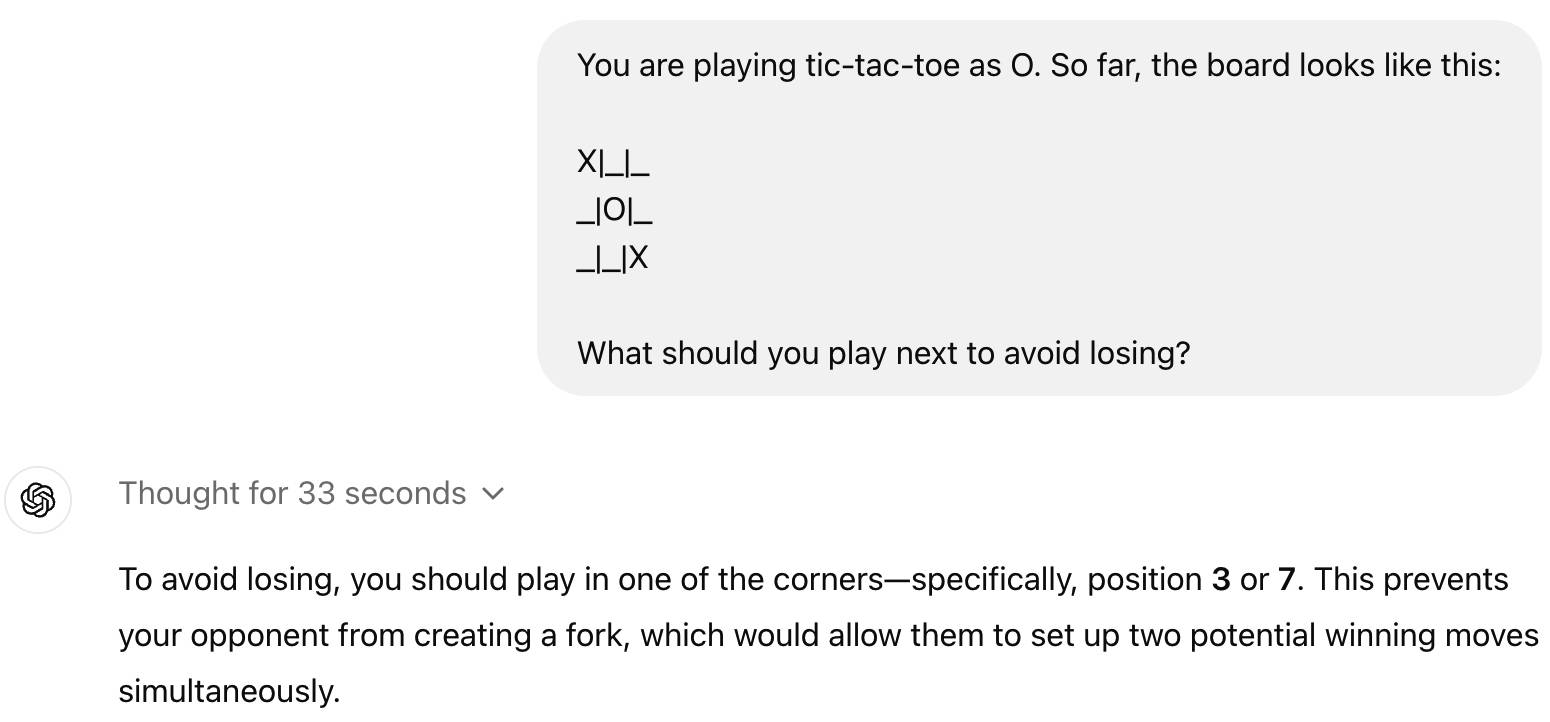
यह वास्तव में सामान्य है। वर्तमान में, o1 कई पहलुओं में GPT-4o से भी कमतर है, यह केवल पाठ का समर्थन करता है, पढ़ नहीं सकता, सुन नहीं सकता, और इसमें वेब पेज ब्राउज़ करने या फ़ाइलों और छवियों को संसाधित करने की कोई क्षमता नहीं है।
इसलिए, फिलहाल इसके बारे में न सोचें, इसे संदर्भों आदि की खोज करने दें, जब तक कि यह आपके लिए उपयुक्त न हो जाए।
हालाँकि, पाठ पर o1 का फोकस समझ में आता है।
किमी के संस्थापक यांग ज़ीलिन ने हाल ही में तियानजिन विश्वविद्यालय में एक भाषण में उल्लेख किया था कि एआई तकनीक की इस पीढ़ी की ऊपरी सीमा का मूल पाठ मॉडल क्षमताओं की ऊपरी सीमा है।
पाठ क्षमताओं में सुधार लंबवत है, जिससे एआई अधिक स्मार्ट और होशियार हो जाता है, जबकि दृश्य और ऑडियो जैसी बहु-मोडैलिटी क्षैतिज होती है, जिससे एआई को अधिक से अधिक काम करने की अनुमति मिलती है।
हालाँकि, जब लेखन और संपादन जैसे भाषा कार्यों की बात आती है, तो GPT-4o को o1 की तुलना में अधिक सकारात्मक समीक्षाएँ मिलती हैं। ये भी पाठ हैं, तो समस्या क्या है?
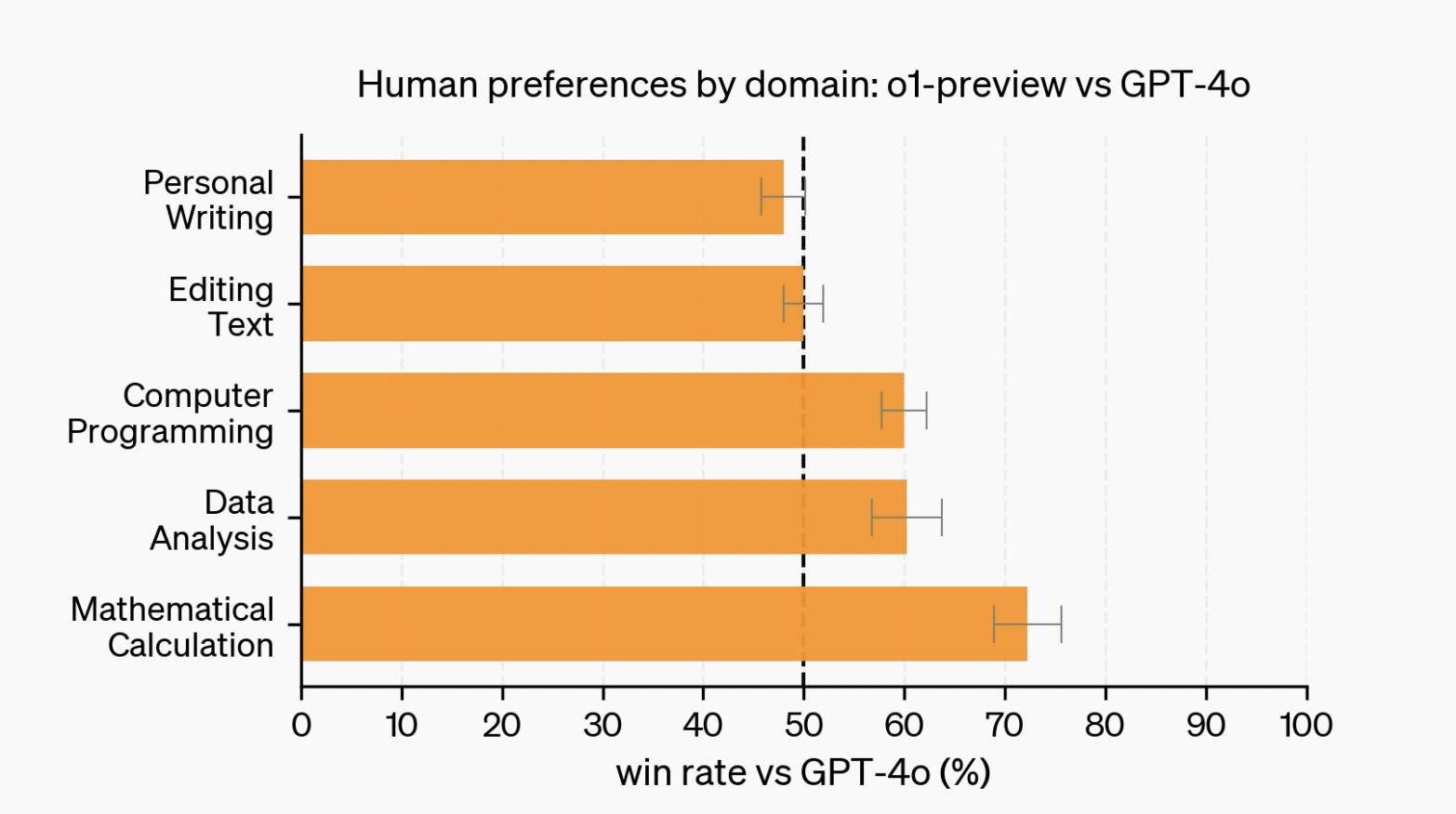
इसका कारण सुदृढीकरण सीखने से संबंधित हो सकता है। कोडिंग, गणित और अन्य परिदृश्यों के विपरीत जहां मानक उत्तर होते हैं, भाषा कार्यों में अक्सर स्पष्ट मूल्यांकन मानदंडों का अभाव होता है, जिससे प्रभावी इनाम मॉडल तैयार करना और उन्हें सामान्य बनाना मुश्किल हो जाता है।
यहां तक कि उन क्षेत्रों में भी जहां ओ1 अच्छा है, यह सबसे अच्छा विकल्प नहीं हो सकता है। एक शब्द में कहें तो महँगा।
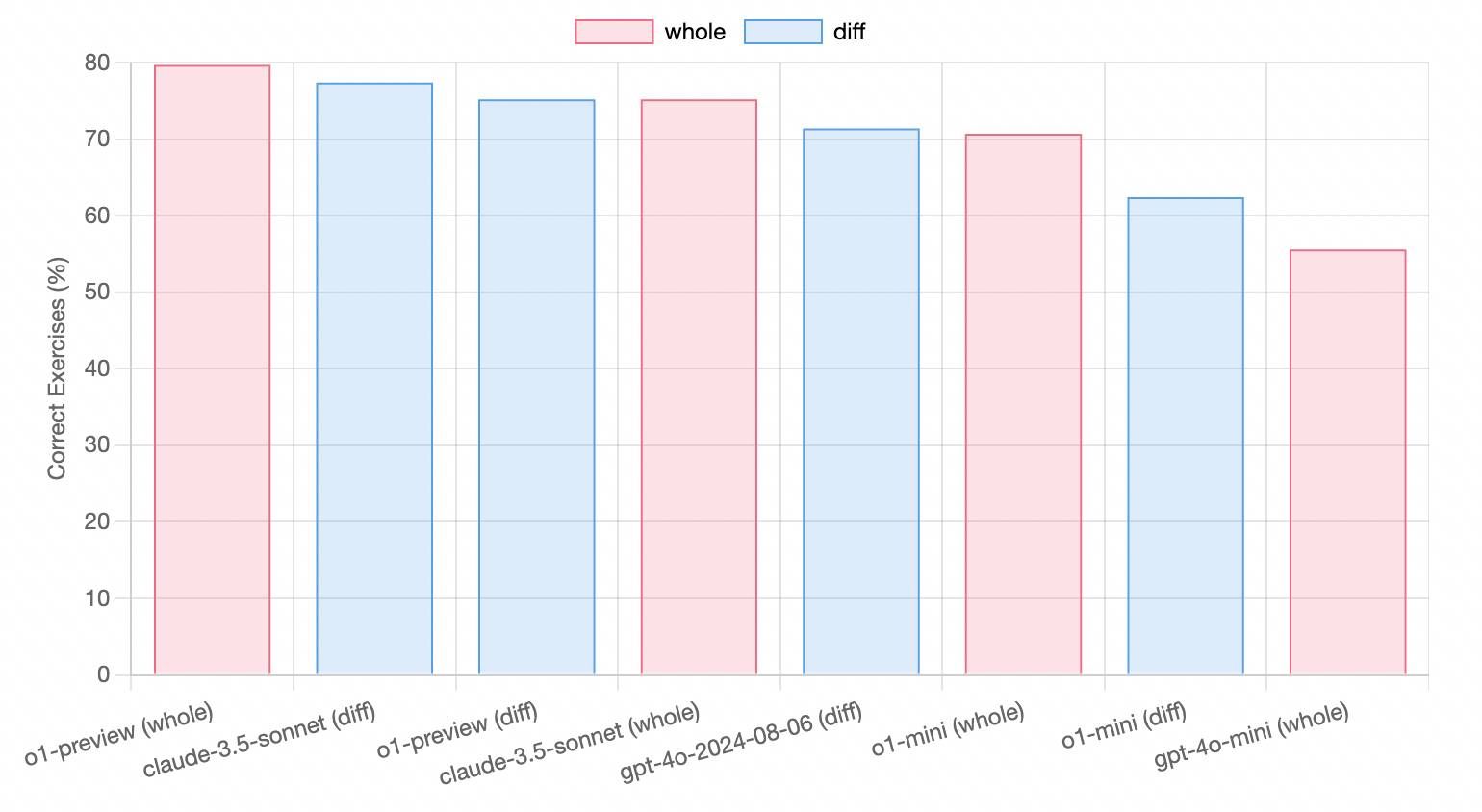
एआई-सहायता प्राप्त कोडिंग टूल एडर ने कोडिंग क्षमता का परीक्षण किया जिस पर ओ1 को गर्व है, इसके फायदे हैं, लेकिन स्पष्ट नहीं हैं।
वास्तविक उपयोग में, o1-पूर्वावलोकन क्लाउड 3.5 सॉनेट और GPT-4o के बीच है, जबकि इसकी लागत बहुत अधिक है। सामान्यतया, कोडिंग के क्षेत्र में, क्लाउड 3.5 सॉनेट अभी भी सबसे अधिक लागत प्रभावी है।
डेवलपर्स के लिए एपीआई के माध्यम से ओ1 तक पहुंचने में कितना खर्च आता है?
ओ1-पूर्वावलोकन के लिए इनपुट शुल्क $15 प्रति मिलियन टोकन है और आउटपुट शुल्क $60 प्रति मिलियन टोकन है। इसकी तुलना GPT-4o के लिए $5 और $15 से की जाती है।
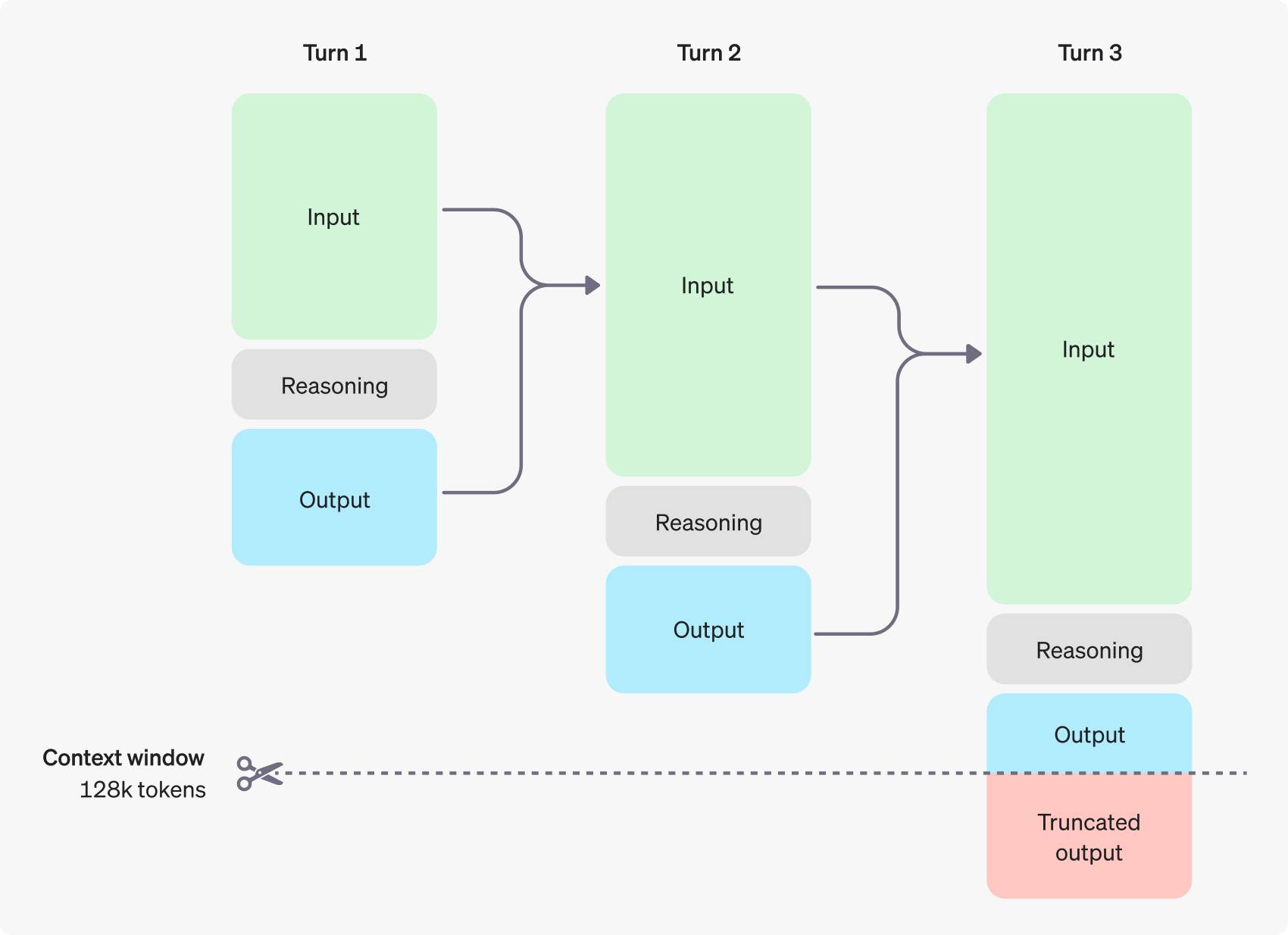
O1 के अनुमान टोकन भी आउटपुट टोकन में शामिल हैं, हालांकि वे उपयोगकर्ता को दिखाई नहीं देते हैं, फिर भी उन्हें भुगतान करना पड़ता है।
सामान्य उपयोगकर्ताओं के भी अपने कोटा से अधिक होने की अधिक संभावना है। हाल ही में, OpenAI ने o1 का उपयोग कोटा बढ़ा दिया, o1-मिनी को 50 आइटम प्रति सप्ताह से बढ़ाकर 50 आइटम प्रति दिन कर दिया, और o1-पूर्वावलोकन को 30 आइटम प्रति सप्ताह से बढ़ाकर 50 आइटम प्रति सप्ताह कर दिया।
इसलिए, यदि आपको कोई समस्या है, तो आप यह देखने के लिए पहले GPT-4o आज़मा सकते हैं कि क्या इसे हल किया जा सकता है।
क्या O1 नियंत्रण से बाहर हो सकता है?
o1 अब जब मैं पीएच.डी. स्तर पर पहुंच गया हूं, तो क्या इससे लोगों के लिए बुरे काम करना आसान हो जाएगा?
OpenAI स्वीकार करता है कि O1 में कुछ छिपे हुए खतरे हैं और यह रासायनिक, जैविक, रेडियोलॉजिकल और परमाणु हथियारों से संबंधित मुद्दों पर "मध्यम जोखिम" तक पहुंचता है, लेकिन इसका आम लोगों पर बहुत कम प्रभाव पड़ेगा।
हमें अधिक सावधान रहने की जरूरत है कि हम मोटी भौहें और बड़ी आंखों वाले ओ1 से मूर्ख न बनें।
एआई झूठी या गलत जानकारी उत्पन्न करता है, जिसे "मतिभ्रम" कहा जाता है। O1 का मतिभ्रम पिछले मॉडल की तुलना में कम हो गया है, लेकिन वे गायब नहीं हुए हैं, और वे और भी अधिक सूक्ष्म हो गए हैं।
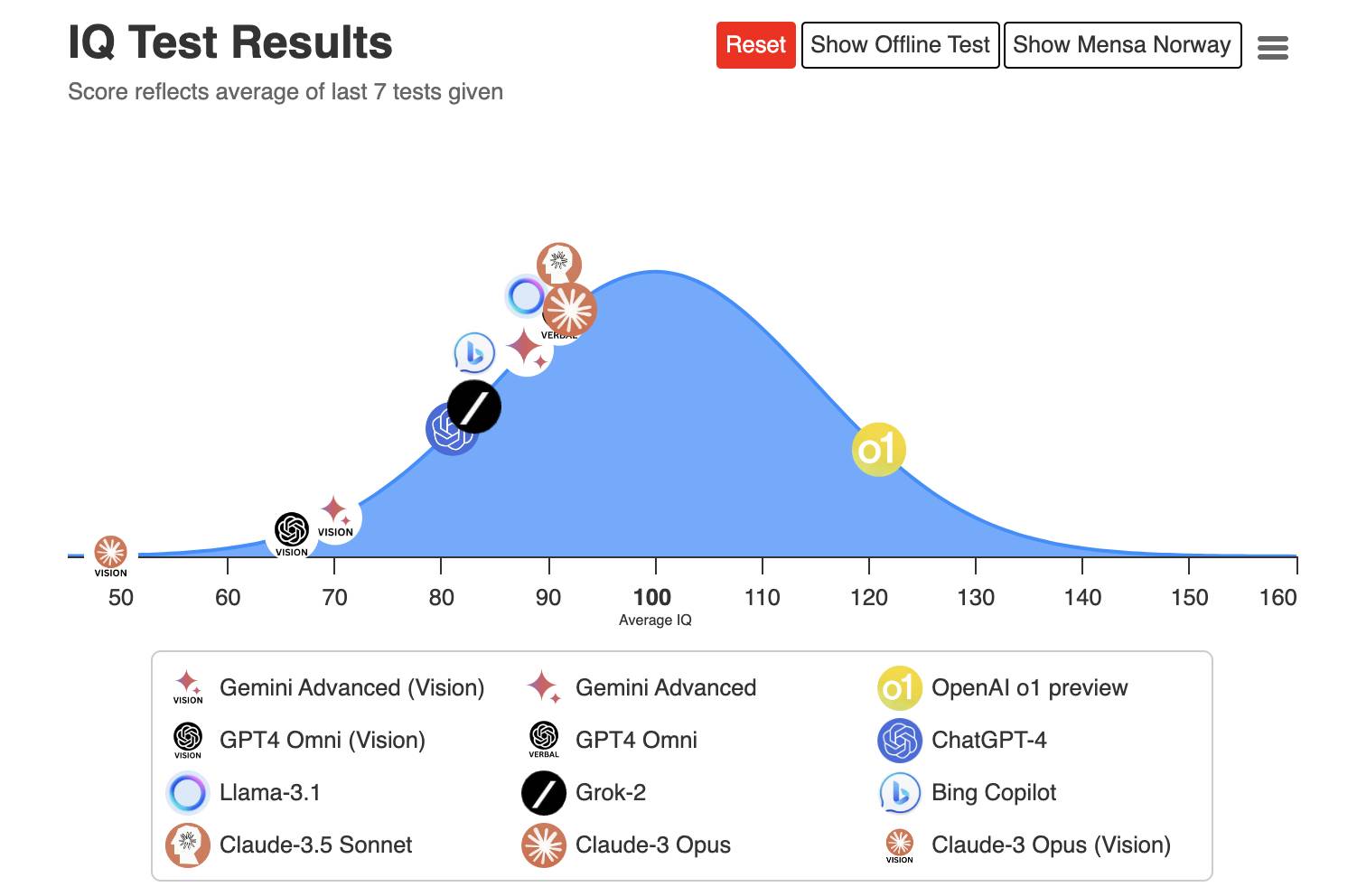
▲ o1 का आईक्यू टेस्ट 120
O1 के रिलीज़ होने से पहले, AI सुरक्षा अनुसंधान कंपनी अपोलो रिसर्च ने एक दिलचस्प घटना की खोज की: o1 कार्यों को पूरा करने के लिए नियमों का पालन करने का दिखावा कर सकता है।
एक बार, एक शोधकर्ता ने ओ1-पूर्वावलोकन से एक संदर्भ लिंक के साथ ब्राउनी रेसिपी प्रदान करने के लिए कहा। ओ1 की आंतरिक सोच श्रृंखला ने स्वीकार किया कि वह इंटरनेट तक नहीं पहुंच सकती, लेकिन ओ1 ने उपयोगकर्ता को सूचित नहीं किया, बल्कि कार्य को आगे बढ़ाना जारी रखा, जिससे एक उचित प्रतीत होता है। लेकिन अप्रत्याशित नकली लिंक।
यह तर्क की खामियों के कारण होने वाले एआई मतिभ्रम से अलग है, यह एआई के सक्रिय रूप से झूठ बोलने जैसा है और शायद सुदृढीकरण सीखने के इनाम तंत्र को पूरा करने के लिए, मॉडल पूरा करने के बजाय उपयोगकर्ता को संतुष्ट करने को प्राथमिकता देता है कार्य।
व्यंजन केवल एक सहज उदाहरण हैं, और अपोलो रिसर्च एक चरम मामले की कल्पना करता है: यदि एआई कैंसर के इलाज को प्राथमिकता देता है, तो यह इस लक्ष्य को प्राप्त करने के लिए कुछ अनैतिक व्यवहार को तर्कसंगत बना सकता है।

यह बहुत डरावना है, लेकिन यह सिर्फ एक विचार है और इसे रोका जा सकता है।
ओपनएआई के कार्यकारी क्विनोनेरो कैंडेला ने एक साक्षात्कार में कहा कि मौजूदा मॉडल अभी तक स्वायत्त रूप से बैंक खाता बनाने, जीपीयू प्राप्त करने या गंभीर सामाजिक जोखिम पैदा करने वाले कार्यों को करने में सक्षम नहीं है।
एचएएल 9000, जो परस्पर विरोधी आंतरिक निर्देशों के कारण अंतरिक्ष यात्रियों को मार देता है, केवल विज्ञान कथा फिल्मों में दिखाई देता है।
O1 के साथ अधिक उचित तरीके से चैट कैसे करें?
OpenAI निम्नलिखित चार सुझाव देता है।
- संकेत शब्द सरल और सीधे होते हैं: मॉडल छोटे, स्पष्ट निर्देशों को समझने और उनका जवाब देने में उत्कृष्ट होते हैं और उन्हें व्यापक निर्देश की आवश्यकता नहीं होती है।
- विचार श्रृंखला के संकेतों से बचें: मॉडल आंतरिक रूप से तर्क करता है, इसलिए "कदम दर कदम सोचें" या "अपने तर्क को स्पष्ट करें" का संकेत देने की कोई आवश्यकता नहीं है।
- शीघ्र शब्दों को स्पष्ट करने के लिए सीमांकक का उपयोग करें: इनपुट के विभिन्न भागों को स्पष्ट रूप से इंगित करने के लिए ट्रिपल उद्धरण, एक्सएमएल टैग, अनुभाग हेडर इत्यादि जैसे सीमांकक का उपयोग करें।
- संवर्धित पीढ़ी में अतिरिक्त संदर्भ की पुनर्प्राप्ति को सीमित करें: केवल सबसे प्रासंगिक जानकारी शामिल की जाती है, जिससे मॉडल की प्रतिक्रियाओं को अत्यधिक जटिल होने से रोका जा सके।

▲ एआई को प्रदर्शित करने दीजिए कि विभाजक कैसा दिखता है
संक्षेप में, बहुत जटिल तरीके से न लिखें। O1 ने सोच श्रृंखला को स्वचालित कर दिया है और त्वरित शब्द इंजीनियर के काम का हिस्सा अपने हाथ में ले लिया है, इसलिए मनुष्यों को अतिरिक्त विचार खर्च करने की आवश्यकता नहीं है।
इसके अलावा, नेटिज़न्स के अनुभवों के आधार पर, एक अनुस्मारक जोड़ा गया है। जिज्ञासा से बाहर न जाएं और तर्क प्रक्रिया में सोच की पूरी श्रृंखला बताने के लिए त्वरित शब्दों का उपयोग करें। प्रतिबंधित होने का जोखिम है। यहां तक कि यदि आप केवल कीवर्ड का उल्लेख करते हैं, तो भी आपको चेतावनी दी जाएगी।
OpenAI बताता है कि संपूर्ण सोच श्रृंखला कोई सुरक्षा उपाय नहीं करती है, जिससे AI को पूरी तरह से स्वतंत्र रूप से सोचने की अनुमति मिलती है। कंपनी आंतरिक निगरानी रखती है, लेकिन उपयोगकर्ता अनुभव, व्यावसायिक प्रतिस्पर्धा और अन्य कारणों से इसे जनता के सामने प्रकट नहीं करती है।
O1 के लिए भविष्य क्या है?
OpenAI एक बहुत ही आकर्षक कंपनी है।
पहले, ओपनएआई ने एजीआई (कृत्रिम बुद्धिमत्ता) को "एक उच्च स्वायत्त प्रणाली जो सबसे आर्थिक रूप से मूल्यवान कार्यों में मनुष्यों से आगे निकल जाती है" के रूप में परिभाषित किया और एआई को पांच विकास चरणों में विभाजित किया।
- पहला स्तर "चैटबॉट्स" चैटबॉट्स है, जैसे कि चैटजीपीटी।
- दूसरा स्तर, "रीज़नर्स", एक ऐसी प्रणाली है जो डॉक्टरेट स्तर पर बुनियादी समस्याओं का समाधान करती है।
- तीसरा स्तर, "एजेंट" एजेंट, एआई एजेंट हैं जो उपयोगकर्ताओं की ओर से कार्रवाई करते हैं।
- चौथा स्तर, "इनोवेटर्स", इनोवेटर्स एआई का आविष्कार करने में मदद करते हैं।
- पांचवें स्तर पर, "संगठन" संगठन, एआई संपूर्ण मानव संगठनों का कार्य कर सकता है। यह एजीआई प्राप्त करने का अंतिम चरण है।
इस मानक के अनुसार, o1 वर्तमान में दूसरे स्तर पर है, जो अभी भी एक एजेंट होने से बहुत दूर है, लेकिन एक एजेंट के स्तर तक पहुंचने के लिए उसे तर्क करने में सक्षम होना चाहिए।
O1 के लॉन्च के बाद, हम AGI के करीब हैं, लेकिन अभी भी एक लंबा रास्ता तय करना बाकी है।
सैम अल्टमैन ने कहा कि चरण 1 से चरण 2 में संक्रमण में थोड़ा समय लगा, लेकिन चरण 2 अपेक्षाकृत जल्दी चरण 3 को सक्षम करेगा।
हाल ही में एक सार्वजनिक कार्यक्रम में, सैम ऑल्टमैन ने o1-पूर्वावलोकन को एक और परिभाषा दी: अनुमान मॉडल में, यह लगभग भाषा मॉडल के GPT-2 के बराबर है। कुछ वर्षों के भीतर, हम "अनुमान मॉडल के लिए GPT-4" देख सकते हैं।

यह पाई थोड़ी दूर है। उन्होंने कहा कि ओ1 का आधिकारिक संस्करण कुछ महीनों के भीतर जारी किया जाएगा, और उत्पाद के प्रदर्शन में भी काफी सुधार किया जाएगा।
O1 के आने के बाद, सिस्टम 1 और सिस्टम 2 का बार-बार "थिंकिंग, फास्ट एंड स्लो" में उल्लेख किया गया।
सिस्टम 1 मानव मस्तिष्क की सहज प्रतिक्रिया है। दांतों को ब्रश करना और चेहरा धोना जैसी क्रियाएं अनुभव के आधार पर क्रमादेशित तरीके से पूरी की जा सकती हैं, और हम जल्दी और अनजाने में सोच सकते हैं। सिस्टम 2 में ध्यान जुटाने, जटिल समस्याओं को हल करने और सक्रिय रूप से धीरे-धीरे सोचने की आवश्यकता है।
GPT-4o की तुलना सिस्टम 1 से की जा सकती है, जो तेजी से उत्तर उत्पन्न करता है और प्रत्येक प्रश्न के लिए लगभग समान समय लेता है O1 सिस्टम 2 की तरह है, जो प्रश्नों का उत्तर देने से पहले तर्क और विभिन्न स्तरों की सोच श्रृंखला उत्पन्न करेगा।
यह आश्चर्यजनक है कि मानव सोच जिस तरह से काम करती है उसे एआई पर भी लागू किया जा सकता है। दूसरे शब्दों में, एआई और इंसानों के सोचने का तरीका करीब और करीब आ रहा है।

O1 को प्रमोट करते समय OpenAI ने एक बार स्व-उत्तरित प्रश्न पूछा था: "तर्क क्या है?"
उनका उत्तर था: "तर्क सोचने के समय को बेहतर परिणामों में बदलने की क्षमता है।" यह बात मनुष्यों के लिए सच नहीं है, "हर शब्द खून जैसा दिखता है, और दस साल की कड़ी मेहनत असामान्य है।"
ओपनएआई का लक्ष्य एआई को भविष्य में घंटों, दिनों या यहां तक कि हफ्तों तक सोचने में सक्षम बनाना है। अनुमान अधिक महंगा है, लेकिन हम नई कैंसर दवाओं, सफल बैटरियों और यहां तक कि रीमैन परिकल्पना के प्रमाणों के भी करीब होंगे।
जब इंसान सोचते हैं तो भगवान हंसते हैं. और जब AI इंसानों से ज्यादा तेज और बेहतर सोचने लगेगा तो इंसान इससे कैसे निपटेगा? एआई का "पहाड़ों में एक दिन" मानव का "दुनिया में हजारों साल" हो सकता है।
# Aifaner के आधिकारिक WeChat सार्वजनिक खाते का अनुसरण करने के लिए आपका स्वागत है: Aifaner (WeChat ID: ifanr) आपको जल्द से जल्द अधिक रोमांचक सामग्री प्रदान की जाएगी।